test.csv 파일을 불러와서 전처리를 한 후, 학습된 모델로 Click Prediction을 수행합니다.
이상으로 Python을 사용하여 Click Prediction 모델을 만드는 예제를 마치겠습니다.
이 예제를 참고하여, 다양한 Click Prediction 만들어 볼 수 있겠습니다.
그리고, 이 예제에서는 LightGBM 라이브러리를 사용하여 모델을 학습하였지만, 다른 머신러닝 라이브러리 또한 사용할 수 있습니다. 이를 통해, 다양한 머신러닝 라이브러리를 비교하여 어떤 라이브러리가 Click Prediction 모델에 더 적합한지 알아볼 수 있습니다.
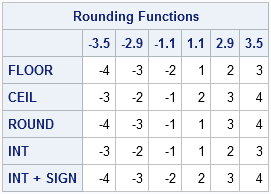
숫자를 다룰 때 가장 많이 사용하는 함수 들은 “floor”, “truncate”, “ceil”, “round”입니다. 이 함수들은 수학적인 개념을 기반으로 하고 있으며, 숫자를 다룰 때 유용하게 사용됩니다. 이번 포스트에서는 “floor”, “truncate”, “ceil”, “round” 함수의 차이점과 각각의 사용 예시에 대해 살펴보겠습니다.
floor 함수
“floor” 함수는 입력된 숫자보다 작거나 같은 가장 큰 정수를 반환합니다. 예를 들어, 3.14의 floor 값은 3이 됩니다.
pythonCopy codeimport math
print(math.floor(3.14)) # 3
print(math.floor(-3.14)) # -4
truncate 함수
“truncate” 함수는 입력된 숫자의 소수점 이하를 제거하여 반환합니다. 양수인 경우 “floor” 함수와 같은 결과를 출력하고, 음수인 경우 “ceil” 함수와 같은 결과를 출력합니다. 예를 들어, 3.14의 truncate 값은 3이 됩니다.
이상으로 “floor”, “truncate”, “ceil”, “round” 함수의 차이점과 사용 예시에 대해 알아보았습니다. 이 함수들은 숫자를 다룰 때 매우 유용하며, 데이터 분석, 수치 계산 등 다양한 분야에서 사용됩니다. 적절한 함수를 사용하여 정확하고 효율적인 작업을 수행할 수 있도록 노력해야 합니다.
커맨드라인 어플리케이션은 콘솔 어플리케이션 이라고도 합니다. 커맨드라인 어플리케이션은 텍스트 인터페이스로 사용하도록 설계된 컴퓨터 프로그램입니다. 쉘 이 그 예입니다. 커맨드라인 어플리케이션은 일반적으로 다양한 인자를 입력값으로 받습니다. 파라미터로 받기도 하고 서브커맨드, 옵션, 플래그, 스위치로도 받습니다.
click 은 최소한의 코드만으로 커맨드라인 인터페이스를 구성할 수 있도록 해주는 파이썬 패키지입니다. 이 “Command-Line Interface Creation Kit” 은 상세한 설정이 가능하지만 그냥 기본값으로 사용해도 아주 좋습니다.
닥옵트(docopt)
docopt 는 가볍고도 아주 파이썬다운 패키지로서 포직스 스타일의 사용법을 파싱하여 커맨드라인 인터페이스를 직관적이고도 쉽게 만들 수 있게 해주는 라이브러리입니다.
플락(Plac)
Plac 은 파이선 표준 라이브러리 argparse 를 선언형 인터페이스를 사용해 그 복잡성을 숨기는 간단한 랩퍼입니다. 매개변수 파서는 명령형으로 작성할 필요가 없습니다. 그냥 추론됩니다. 이 모듈은 복잡한 걸 원치 않는 사용자, 프로그래머, 시스템 관리자, 과학자 및 일회용 스크립트를 작성하는 대신 커맨드라인 인터페이스를 빠르고 간단하게 개발하고자 하는 사람들을 대상으로합니다.
클리프(Cliff)
Cliff 는 커맨드라인 프로그램을 개발하기 위한 프레임워크입니다. setuptools를 엔트리포인트로 사용하여 서브캐맨드, 출력 포맷터 및 기타 확장을 제공합니다. 이 프레임워크는 svn 과 git 처럼 다단계 명령을 만드는 데 사용됩니다. 여기서 메인 프로그램은 몇 가지 기본적인 인자값 구문 분석을 처리한 다음 서브커맨드를 호출하여 작업을 수행합니다.
시멘트(Cement)
Cement 는 진보된 CLI 어플리케이션 프레임워크입니다. 그 목표는 간단한 커맨드라인 애플리케이션과 복잡한 커맨드라인 어플리케이션 모두를 위한 표준 및 기능이 풍부한 플랫폼을 도입하고 품질 저하없이 신속한 개발 요구 사항을 지원하는 것입니다. 시멘트는 유연하며 그 사용 사례는 간단한 마이크로 프레임워크에서 복잡한 대규모 프레임워크에 이르기까지 다양합니다.
파이썬 파이어(Python Fire)
Python Fire 는 파이썬 객체를 전혀 사용하지 않고도 자동으로 커맨드라인 인터페이스를 생성하는 라이브러리입니다. 커맨드라인에서 파이썬 코드를 보다 쉽게 디버깅하고, 기존 코드에 대한 CLI 인터페이스를 생성하고 REPL에서 인터렉티브하게 코드를 탐색하고, 파이썬과 Bash(아니면 다른 쉘) 간의 전환을 단순화 할 수 있습니다.