SQL에는 쿼리를 실행할 때 그 순간만 사용할 테이블을 잠깐 만들어서 사용할 수 있습니다.
이때 JOIN절에서 임시 테이블을 만드는 방법과 select하기 전에 with절로 임시 테이블을 만드는 방법이 있습니다.
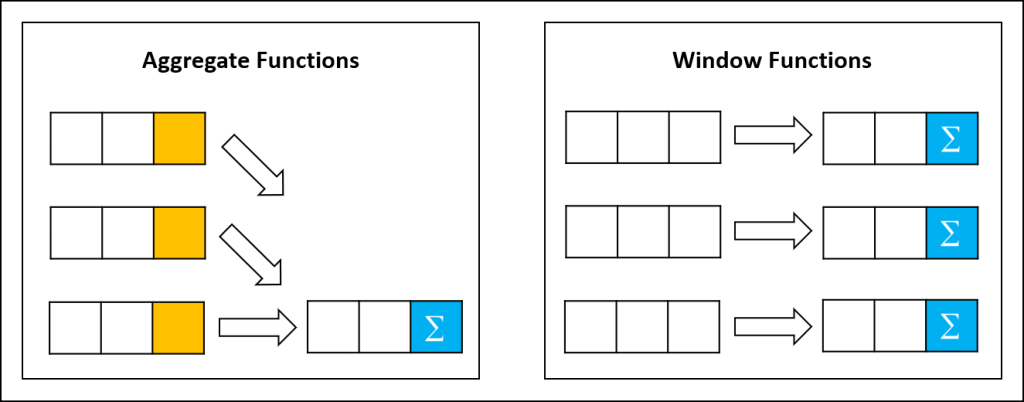
쿼리 내에서 임시 테이블을 만드는 방법 2가지
- 인라인뷰(Inline view): Join 구문에서 select를 사용해서 쿼리를 실행하고 이름을 붙여 테이블 처럼 사용
- CTE (Common Table Expression): select하기 전에 with절로 select 구문을 묶어서 이름을 붙이고 공통 테이블처럼 사용
CTE의 장점은 한 번 작성하고 뒤에서 이름을 이용해서 여러번 참조할 수 있다는 장점이 있습니다.
다시 정리하면
CTE (Common Table Expression)
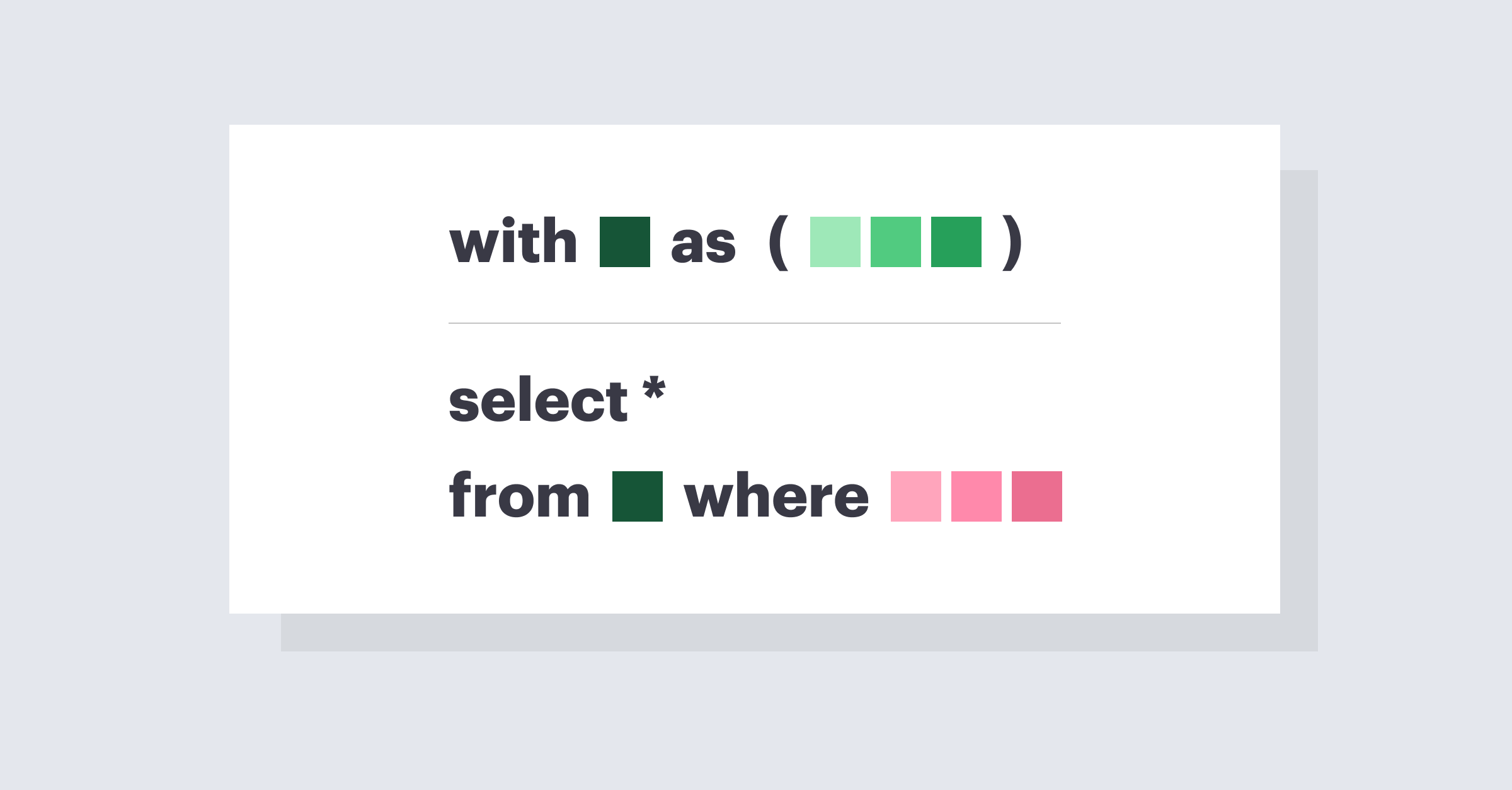
CTE (Common Table Expression)는 SQL 쿼리에서 일시적으로 사용되는 결과 세트를 정의하는 방법입니다. CTE는 복잡한 쿼리를 간단하게 만들고, 코드를 재사용하며, 가독성을 높여주는 도구입니다. CTE는 ‘WITH’ 절을 사용하여 정의되며, 이어지는 SELECT, INSERT, UPDATE, DELETE 문에서 참조할 수 있습니다.
MariaDB에서 CTE를 사용한 예제:
단순한 CTE 예제 (사용자 정보 가져오기):
WITH user_cte AS ( SELECT id, name, age FROM users ) SELECT * FROM user_cte;
이 예제에서는 user_cte라는 CTE를 생성하고, users 테이블에서 id, name, age를 가져옵니다. 그 다음, user_cte를 참조하여 결과를 가져옵니다.
재귀 CTE 예제 (계층적 카테고리 정보 가져오기):
WITH RECURSIVE category_cte (id, parent_id, name, depth) AS ( SELECT id, parent_id, name, 0 FROM categories WHERE parent_id IS NULL UNION ALL SELECT c.id, c.parent_id, c.name, p.depth + 1 FROM categories c JOIN category_cte p ON c.parent_id = p.id ) SELECT * FROM category_cte ORDER BY depth, id;
이 예제에서는 category_cte라는 재귀 CTE를 사용하여, 계층적 카테고리 정보를 가져옵니다. 초기에는 상위 카테고리(즉, parent_id가 NULL인) 정보를 가져온 후, UNION ALL을 사용하여 하위 카테고리 정보를 가져옵니다. 그 다음, category_cte를 참조하여 결과를 가져옵니다.
다중 CTE 예제 (사용자 정보와 주문 정보 동시에 가져오기):
이 예제에서는 두 개의 CTE를 생성합니다. user_cte에서는 사용자 정보를 가져오고, orders_cte에서는 주문 정보를 가져옵니다. 그 다음, 두 CTE를 조인하여 결과를 가져옵니다.