과학기술정보통신부 홈페이지에 방문하면 무선통신서비스 가입회선 통계 데이터를 제공하고 있어서 아무나 받아서 사용할 수 있습니다. 수작업으로 하는 것이라서 이전 달의 자료를 다음 달 말일 정도에 업데이트 해줍니다.
그러니까 2월달 자료는 3월말경에 업데이트가 됩니다.
자료가 올라오는 시기가 1개월 가까이 차이가 있어서 이전 달의 내용을 달이 바뀌고 나서 바로 볼 수 없는 것이 흠입니다만
없는 것 보다는 훨씬 낫습니다. PDF로 제공하는 것도 좀 불편합니다. 포맷을 바꾸기가 조금 번거롭습니다.
엑셀 파일로 해주셨으면 더 좋았을텐데요.
이 자료 얘기를하는 것은 최근에 업무와 관련해서 통신서비스 관련 분석 작업을 조금하게 되었는데 작업을 하고난 김에 저 데이터를 예제로 간단한 시각화 예제를 만들어 보기로 했습니다.
실제 업무에서는 저 데이터와 다른 데이터를 결합해서 확인하거나 하는 것이지만 이 포스트에서는 저 데이터만 이용해서 아주 간단한 EDA작업을 해보겠습니다.
2018년 3월까지의 데이터를 사용했습니다.
이 글을 쓰는 시점은 2018년 5월입니다
소스 코드
플롯(plot)을 그리는데 ggplot2를 사용했고 데이터 랭글링(data wrangling)은 dplyr와 tidyr를 사용했습니다. tidyverse 패키지에 몽땅 같이 들어 있으므로 한 번에 묶음 패키지를 통째로설치하고 싶으면 tidyverse만 설치하면 됩니다.
tidyverse는 ggplot2를 포함한 몇개의 유용한 패키지 를 묶어 놓은 것입니다.
아래 코드에 주석을 적어 두었습니다. 그래서 코드 설명은 따로 하지 않겠습니다. dplyr와 tidyr에 익숙하지 않은 분들은 패키지 사용법을 잠깐 살펴봐야 할 수있습니다. 이것도 여기서는 설명하지 않겠습니다. 너무 길어집니다.
전체 코드는 다음과 같습니다.
# 무선 통신 서비스 # msu : mobile service users library(tidyverse) msu <- read.csv(file="./2018년 3월 기준 - 무선통신서비스 가입회선 통계.csv") colnames(msu) msu_molten <- msu %>% gather(월, 가입자, -구분, -통신사) # 월의 문자열을 날짜 타입으로 바꿉니다 msu_molten <- msu_molten %>% mutate(월=as.Date(paste0(월, ".1"), format="X%Y.%m월.%d")) msu_molten <- msu_molten %>% filter(구분 != "합 계" & 통신사 != "소계") # 데이터를 잘 집계해서 플롯을 몇개 그려봅니다 가입구분별_데이터 <- msu_molten %>% group_by(구분, 월) %>% summarise(가입자=sum(가입자)) ggplot(가입구분별_데이터, aes(x=월, y=가입자, fill=구분)) + geom_area(colour="black", size=.2, alpha=.4) + scale_fill_brewer(breaks=rev(levels(가입구분별_데이터$구분))) 통신사별_데이터 <- msu_molten %>% group_by(통신사, 월) %>% summarise(가입자=sum(가입자)) ggplot(통신사별_데이터, aes(x=월, y=가입자, colour=통신사)) + geom_line() + scale_fill_brewer(breaks=rev(levels(통신사별_데이터$통신사))) 통신사별_3월_합계 <- msu_molten %>% filter(월=="2018-03-01") %>% group_by(통신사, 월) %>% summarise(가입자=sum(가입자)) ggplot(통신사별_3월_합계, aes(x=통신사, y=가입자, fill=통신사)) + geom_bar(stat="identity") 월별_3월 <- msu_molten %>% filter(월=="2018-03-01" & 구분 != "합 계" & 통신사 != "소계") %>% mutate(구분=as.character(구분), 통신사=as.character(통신사)) # 모자이크 플롯 library(ggmosaic) ggplot(data=월별_3월) + geom_mosaic(aes(weight=가입자, x=product(통신사), fill=구분)) # 카이제곱 검정 표 <- 월별_3월 %>% select(-월) %>% spread(통신사, 가입자) %>% select(-구분) chisq.test(as.matrix(표))
한글 변수도 몇개 사용했고 줄이 길어서 조금 복잡해 보일텐데요. 복사해서 sublime text 같은 편집기나 Rstudio에서 보세요. 원래 한글 변수명은 잘 안쓰지만 한 번 해보고 싶었습니다. 가끔은 일탈이 필요해요.
에어리어 플롯 – area plot
가입유형별 시계열 에어리어 플롯(time-series area plot)입니다. 케이크 차트(cake chart)라고도 부릅니다.
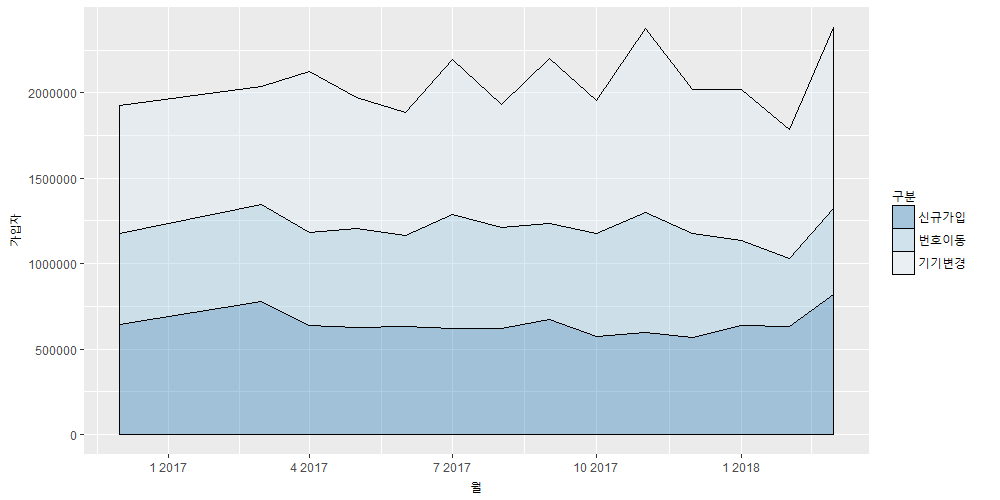
월별 집계이기 때문에 월별로 가입유형의 변화추세를 볼 수 있습니다.
신규가입자와 기기변경이 많네요.
이전 달에 비해서 큰 폭으로 늘었다는 것을 볼 수 있습니다.
시계열 플롯 – time-series plot
통신사별 시계열 라인플롯입니다. 통신사별, 월별로 가입자를 모두 취합했습니다.
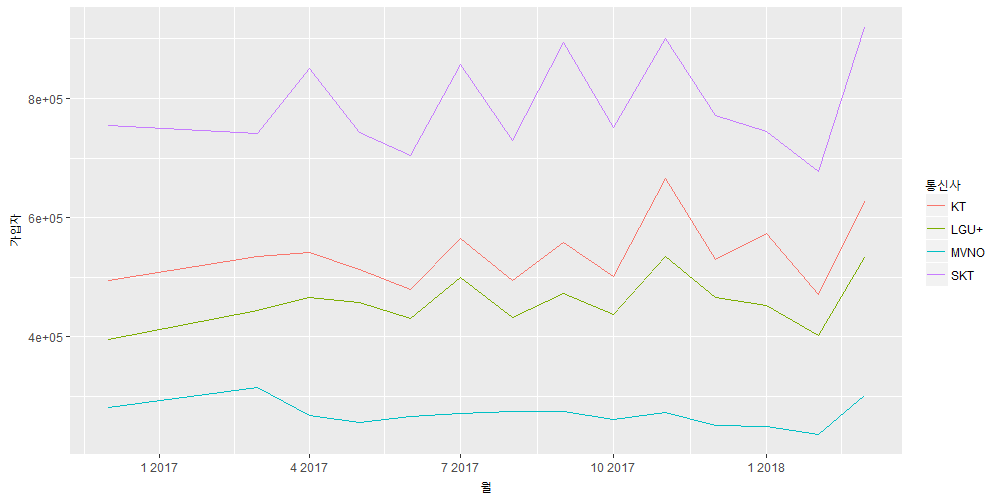
SKT의 가입자가 월등히 많은 것을 볼 수 있습니다. 증가폭도 큽니다. 다른 통신사와 MVNO도 큰폭으로 상승하긴 했습니다.
2월에 가입자가 조금 적은데 어떤 이슈가 있었거나 3월에 있을 이벤트를 사람들이 기다렸을 가능성이 큽니다.
봄 철에는 여러 이벤트가 많은 편인데 새모델이 출시된다거나 요금할인이 된다거나 또는 대학신입생들의 입학 기념품이거나 신학기 행사이거나요. 그래서 2월에는 가입을 하지 않고 3월까지 기다렸을 가능성이 큽니다.
반대로 해석하면 기업들은 통상 3월부터 이벤트를 많이합니다. 주변정보 탐색을 해보지 않았고 부가정보가 없어서 모르지만 상식만으로 그렇게 추측해 봅니다.
위의 가설은 실제로 데이터를 확인하거나 서베이를 해서 확인해 보지 않았기 때문에 논리에 기반한 소설일 뿐입니다
바 플롯 – bar plot
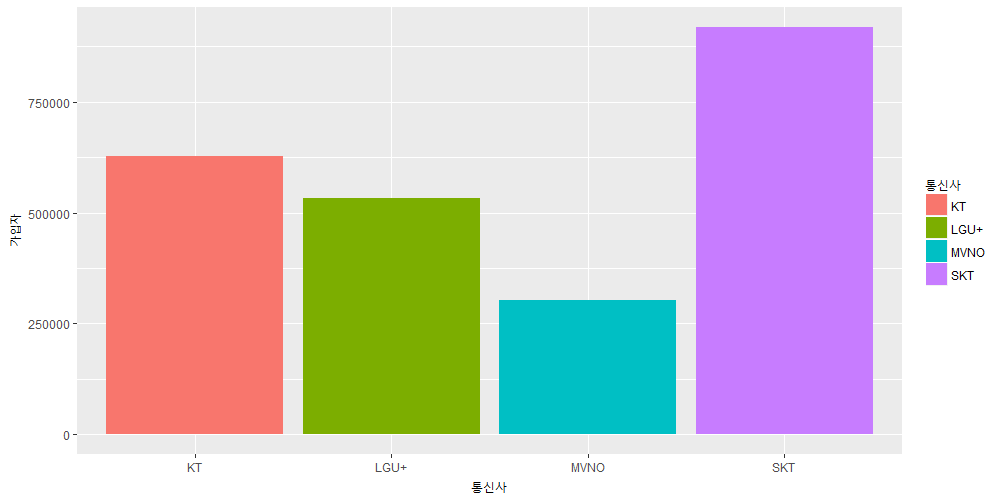
색깔은 기본값으로 막 칠했습니다. 알록달록하게. 나이 먹으면 알록달록한게 좋아집니다.
그냥 2018년 3월의 가입자수를 통신사별로 수치 비교 하기 위해 바 플롯을 그린 것입니다. 바 플롯(bar plot)이라고도 하지만 그냥 막대 차트(bar chart)라고 더 많이 부릅니다. 어쨌는 플롯을 보면 SKT의 가입자가 월등히 많네요.
모자이크 플롯 – mosaic plot
통신사별 구분별로 모자이크 플롯을 그렸습니다.
2차원으로 된 것으로 빈도의 비중을 비교할 때 유용한 플롯입니다.
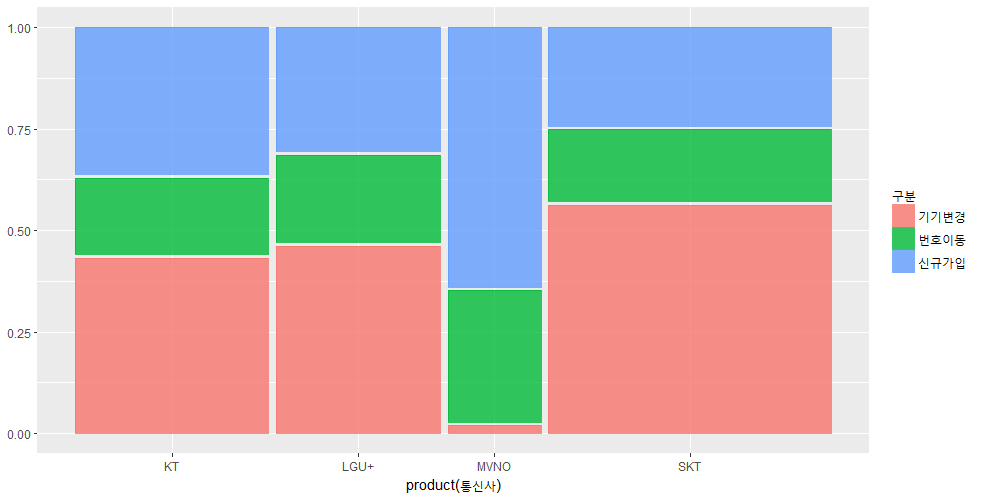
크기가 큰 것이 많은 것입니다. 사각형의 크기를 보고 비중을 보면 됩니다.
아 쉽다. 전 이런게 좋아요. 쉬운거
그림을 보면 SKT의 기기변경 사용자가 가장 많습니다. 그 다음은 비교하기 애매하지만 KT의 기기변경과 SKT의 신규가입자가 많은 것 같습니다.
MVNO는 신규가입자의 비율이 매우 높습니다. (왜 그럴까요??)
SKT의 기기변경 비율이 다른 통신사에 비해서 높습니다.
KT는 신규가입자의 비율이 다른 통신사에 비해서 높습니다.
2018년 3월은 SKT에 기기변경으로 가입한 사람이 많고 KT는 처음 진입한 사람이 많다고 볼 수 있습니다. 모든 통신사에 걸쳐 처음 가입했다고 하면 이제 막 성인이 되었거나 외국에서 왔거나 일 것 같습니다.
어쨌든 뭐로 보든 SKT 가입자가 많군요. SKT는 통신사 중에서 무선 점유율이 가장 높은 회사로 알려져 있습니다.
여전히 장사 잘되나 봅니다.
마지막으로 소스코드에서 카이제곱 검정(chi-square test)을 했습니다만 별 의미 없는 것입니다. 결과는 귀무가설 기각으로 통신사 구분과 가입종류의 구분은 서로 독립이 아니다. 즉 “영향이 있다” 정도입니다. 이건 가설검정을 하지 않아도 모자이크 플롯으로 봐도 쉽게 알 수 있긴합니다. 하지만 검정법을 사용해서 뭐든 확실하게 한 번 보는게 좋습니다.
여기까지입니다.
사실 너무 대충 하다만 EDA입니다만 데이터를 보고 요약을 정리해 나가다 보면 뜻하지 않는 인사이트를 발견하기도 합니다. 물론 이 데이터는 집계가 너무 많이 되어 있어서 주변정보가 없는 상태에서 특별한 인사이트를 얻기는 어렵습니다.
데이터는 아래 링크를 클릭해서 받으세요.
파일 다운로드: 2018-3-mobile-user-data









