요 며칠 사이에 R관련 커뮤니티에서 새소식으로 메일이 날아오고 있는데 가장 많이 보이는 것이 RStduio v1.0이 릴리즈 되었다는 것입니다.
바꿔 말하면 그동안 RStduio의 버전이 0.x대 였다는 것이지요.
2011년 2월에 0.92로 메이저(major) 릴리즈가 공개되고 2016년 11월 2일에 버전 1.0을 넘기게 되었습니다. 오래 걸렸네요.
중요한 업데이트 내용은 공식 블로그를 보시면 되겠습니다.
https://blog.rstudio.org/ 여기를 가보시면 되지만
귀찮아 하실 분들을 위해서 업데이트 내용을 간단히 정리해 보면 다음과 같습니다.
R Notebooks 지원
iptyhon-notebook이나 기타 다른 분석 인터페이스에서 유행처럼 지원하는 notebook 기능을 지원합니다. 단 포맷이 Rmd(R markdown 형식) 이므로 다른 노트북 보다는 더 유연한다고 할 수 있습니다. Rmd파일을 그대로 Notebook으로 인식합니다.
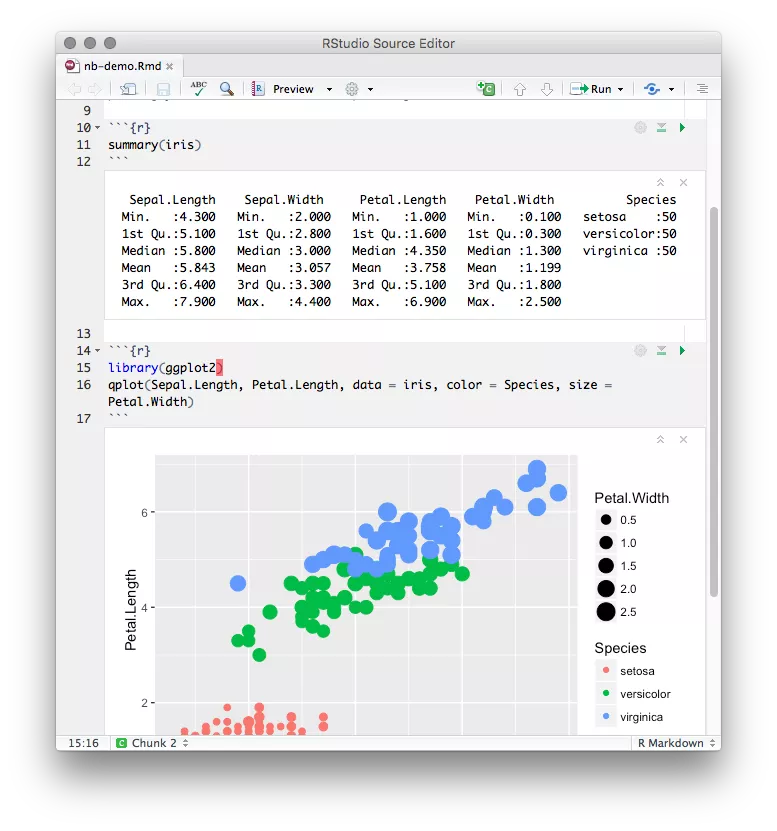
물론 R은 원래 반 대화형 모드(interactive mode)로 코드의 중간부분만 선택해서 따로 실행할 수 있기 때문에 Notebook 기능을 지원하지 않아도 노트북 흉내를 낼 수 있었습니다.
R Notebook은 다른 노트북 처럼 입력창의 중간중간에 결과를 확인할 수 있다는 장점이 있어 훨씬 직관적입니다.
이제 Notebook 흉내가 아닌 Notebook 기능을 그대로 쓸 수 있습니다.
chunk(청크; R markdown내에 듬성듬성 있는 R코드 영역)에 대한 부분만 따로 실행하거나 전체를 실행해서 preview하거나 할 수 있습니다.
그 외에도 노트북은 수식이나 문장 사이에 삽입하는 코드들에 대한 대화형 모드를 같이 지원합니다.
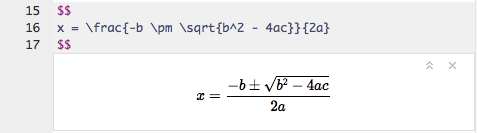
위 그림과 같이 LaTex으로 수식을 입력하는 등의 것들입니다.
Spark with sparklyr
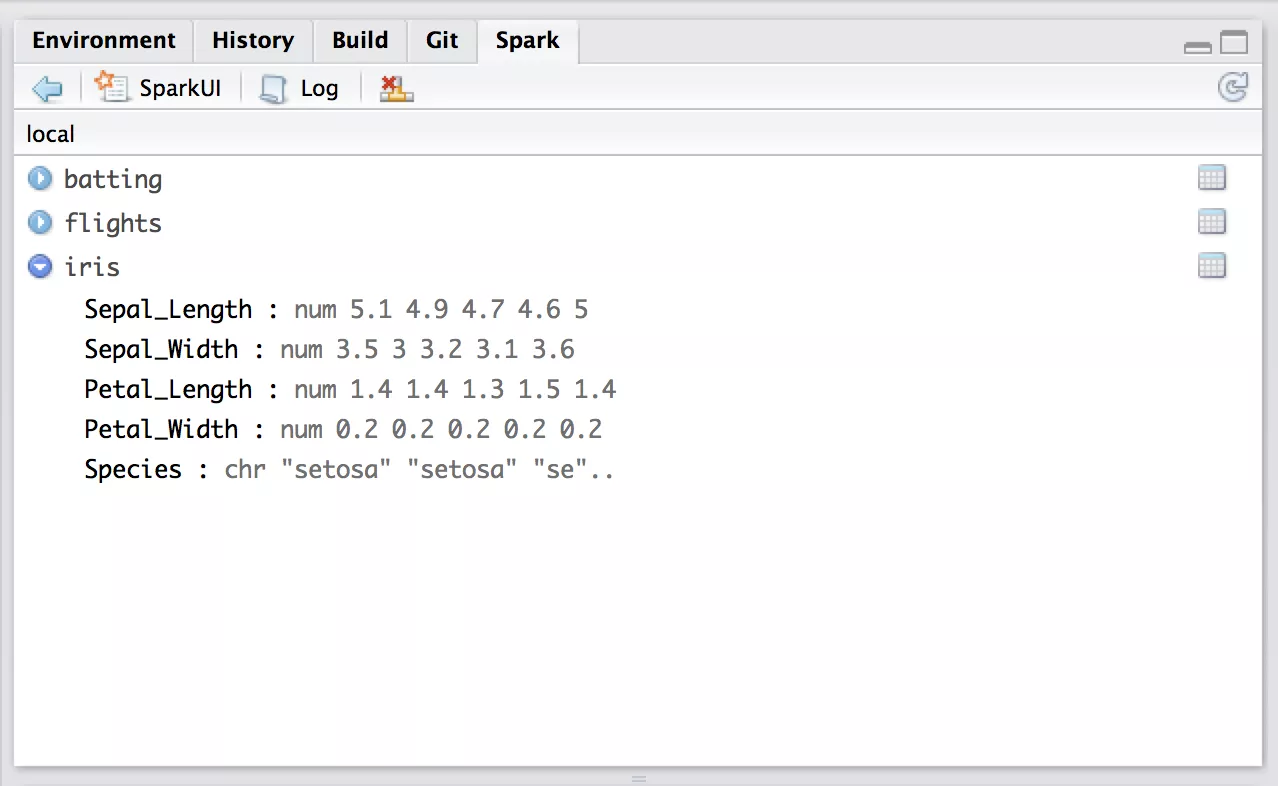
sparkyr 패키지를 이용해 Spark(스파크)를 지원합니다. Spark내에 있는 dataframe을 RStduio에서 미리보기 하거나 할 수 있다고 합니다.
아직 테스트 해보지는 않았지만 조만간 해봐야겠습니다.
Profvis 패키지를 이용한 프로파일링
보통의 다른 랭귀지들은 IDE(통합개별환경)에서나 또는 별도의 도구를 이용해서 profiling(프로파일링)을 할 수 있습니다.
실행되는 코드중에서 어느 부분이 얼마만큼의 시간과 자원을 소비하는지에 대한 트레이싱인데 RStduio가 이제 profiling을 지원한다는 얘기입니다.
어느 구간에서 가장 오랜 시간이 걸렸는지 시각화해서 보여줍니다.
화면은 대충 아래와 같습니다.
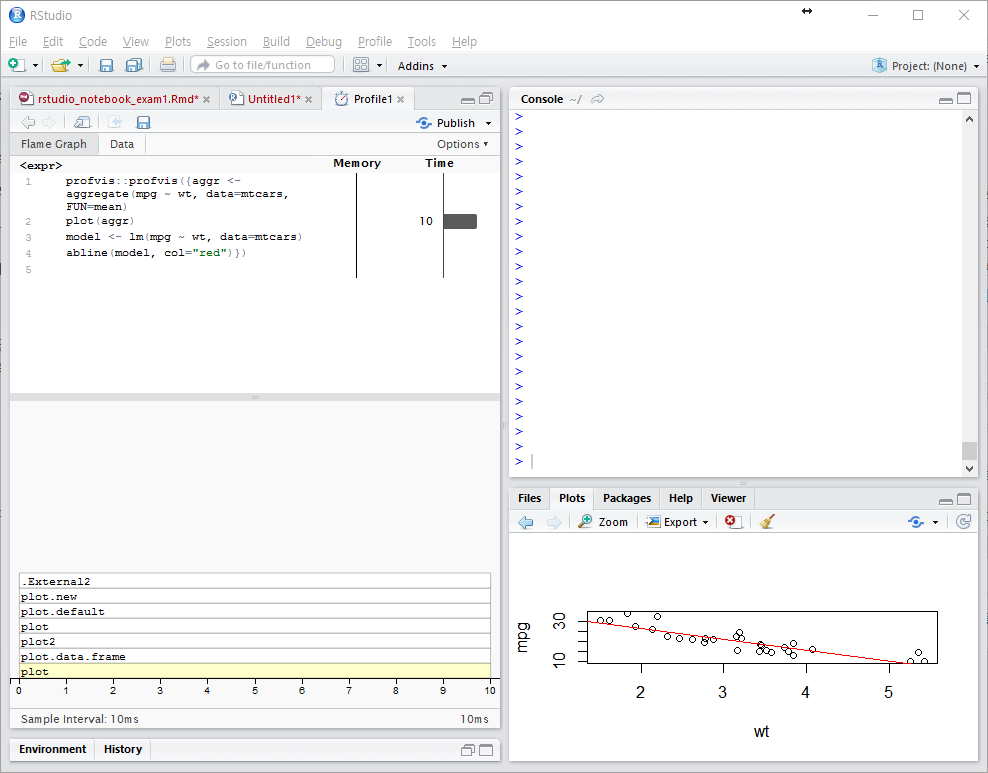
코드를 입력하고 코드를 선택한 후에 Profile 메뉴를 눌러주면 됩니다. (어렵지 않아요.^ㅡ^)
Data Import(데이터 적재) 기능 강화
File 메뉴의 Data Import 메뉴를 이용해서 File이나 URL에 대한 파일의 미리보기 기능을 지원합니다. 하지만, 공식 블로그에 적힌 예제를 실행했더니 에러가 나더군요.
파일에 따라 에러가 발생하는지 아닌지는 확인해 보지 않았습니다.
제 작업환경이 이상한 것인지도 모릅니다. 버그라면 뭐 나중에 고쳐주겠죠. (우선 포기…)
그외에 다른 기능에 대한 내용은 없습니다. RStduio 최신 버전을 유지하고 계셨다면 위에 열거된 내용 빼고는 큰 차이는 없어 보입니다.
그리고 더불어서 RStudio Server도 v1.0을 넘겼습니다. 공식 블로그에서는 따로 언급이 없지만 위에 기능들이 함께 지원되었을 가능성이 큽니다.