오래된 Ubuntu 14.04에 Python 3.7을 설치할 때 필요한 간단한 절차입니다. 이 글을 쓰는 시점에서의 최신 Ubuntu 18.04이고 곧 20.04 버전이 나올 예정입니다.
그리고 현재 Python은 3.7.x가 최신 버전인데 Ubuntu 14.04에는 3.6.x가 설치되어 있고 14.04에 3.7.x는 그냥은 설치되지 않습니다.
3.6.x를 그냥 쓰면 되지 않겠냐고 하겠지만 3.6과 3.7은 마이너 버전 하나의 차이로 보이지만 실제로는 많은 부분에서 차이가 있습니다. 성능, 보안, 문법과 같은 것들입니다. 최신 패키지들도 3.6에서는 오작동하는 사례가 많습니다. 3.7을 설치해서 사용하는 것이 좋습니다.
sudo apt update # 깨끗하게 한번 apt 정보 갱신
sudo apt install software-properties-common # add-apt-repository 명령어를 설치하기 위한 것
sudo add-apt-repository ppa:deadsnakes/ppa # 레파지토리를 등록합니다.
sudo apt update # apt에 정보를 업데이트합니다.
sudo apt install python3.7 # python 3.7을 설치합니다.
이 차이를 모르면 소숫점이 있는 수치 계산을 하다가 반올림 처리 방식의 차이로 인해 오차가 생겼다고 생각하고 정합성을 맞추려다 헤메는 경우가 있을 수도 있습니다.
물론 평생 이런 일이 없을 수도 있습니다.
제가 학생이던 시절에 금전 계산을 자동으로 복잡하게 하는 정산 소프트웨어를 의뢰받아 만든 적이 있었는데, 의뢰인이 제시해준 계산 방법과 확인용 정산 출력물을 기반으로 계산 소프트웨어를 작성하는 흐름으로 진행했었습니다. 단위 계산이 조금 복잡했고 반복 계산을 한 뒤에 복잡하게 역산하는 것을 한 뒤에 총 결과를 산출하는 것이었습니다. 요즘 용어로 바꾸자면 최적화 비슷한 것이었습니다.
그런데 문제가 생겼습니다. 만들 때 적은 양의 데이터로 단위 계산을 몇 개 실험해서 해본 뒤에 나온 결과를 보고 정확하게 계산되었는지를 정확하게 확인했고 문제가 없었습니다, 그 후에 전체 계산을 수행하는 것을 진행해서 총합을 확인해보니 정답지와 결과값이 미세하게 달랐습니다. 다시 단위 계산을 몇개 임의로 선택해서 결과가 어떻게 다른지 점검해 봤는데 몇개가 다르게 나온다는 것을 알았습니다. 이 문제의 원인을 찾느라 시간을 쓸데없이 허비한 적이 있습니다.
물론 이 차이로 인해 큰 일이 생기는 것은 아니었습니만 숫자는 틀려도 문제의 원인을 알지 못하면 곤란하다는 의뢰인의 말에 원인을 찾아야 했습니다.
찾아 본 결과 원인은 제가 사용하던 컴퓨터 랭귀지에서 제공하는 round 함수가 사사오입이 아닌 뱅커스 라운딩을 채택했기 때문에 발생한 문제였고 round 함수를 사사오입 방식의 다른 round로 변경해서 해결했었습니다. 그 뒤로는 round를 하게될 일이 있으면 반드시 사용하는 소프트웨어의 round가 사사오입 방식인지 뱅커스 라운딩인지 확인을 하고 작업을 시작하는 습관이 있습니다. 그게 아니면 오차가 좀 크더라도 정합성을 위해서 무조건 소숫점이하는 절사 시켜버리곤 했습니다. 물론 요즘은 이것마저도 잘 하지 않는 늙은이가 되었습니다만.
어쨌든 그 당시에는 컴퓨터 랭귀지의 기본 함수에 버그가 있는 줄 알고 컴파일러 판매회사에 문의하려고 했었으나 함수 매뉴얼을 먼저 찾아보니 천절하게 설명을 해 두었더군요. 함수 매뉴얼을 자세히 읽지 않은 제가 문제였던 것이고 그리고 관련 자료를 더 찾아보고는 제가 반올림에 대해서 상당히 무식했다는 사실을 알았습니다.
“세상에 반올림 방법은 딱 하나 인 줄 만 알았어” 라고 생각했습니다. 배운 것이 그것뿐이라서요.
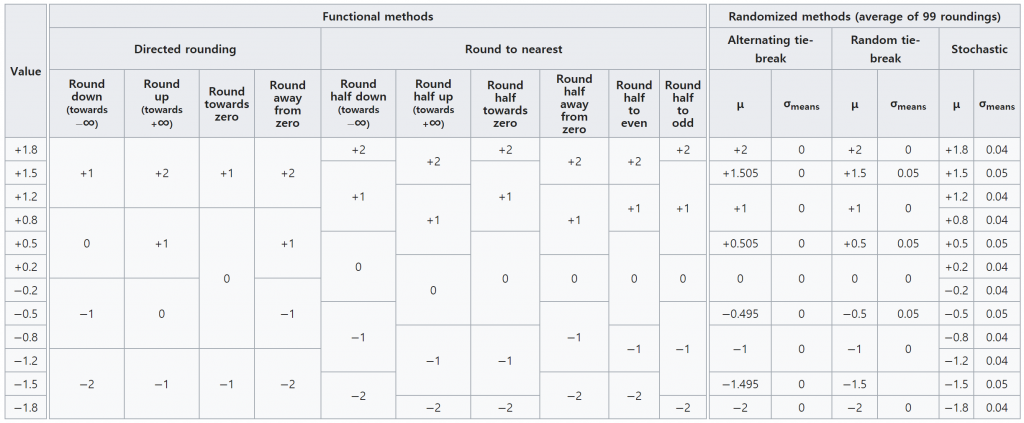
앞서 말씀드린 것 처럼 반올림은 여러가지 방식이 있습니다. 꽤 많은 방식들이 있습니다만 우리가 흔히 접할 수 있는 것은 위에서 말한 2가지인 사사오입과 뱅커스 라운딩입니다. 이 포스트에서 사사오입과 뱅커스라운딩의 차이를 설명하겠습니다.
사사오입( 四捨五入 ) 반올림
우선, 흔히 아는 반올림은 사사오입인데 4는 버림, 5는 올림을 뜻합니다. 보통은 우리는 그냥 “반올림”이라고 하지만 명확환 구분과 설명을 위해서 “사사오입”이라고 하겠습니다. 사사오입 방식은 영어로는 Round, away from zero (0으로부터 멀어지는 이라는 뜻) 라고 합니다. 사사오입으로 소숫점이 있는 숫자들을 정수로 반올림한다고 하면 다음과 같은 결과가 나옵니다.
0.4 반올림 하면 0 0.5 반올림 하면 1 0.6 반올림 하면 1 1.4 반올림 하면 1 1.5 반올림 하면 2 1.6 반올림 하면 2 2.4 반올림 하면 2 2.5 반올림 하면 3 2.6 반올림 하면 3
잘 알고 있는 그 방식입니다.
뱅커스 라운딩 (오사오입 반올림)
뱅커스 라운딩은 올려질 값이 5인 경우에 만들어질 수의 끝이 짝수가 되도록(짝수에 수렴) 하는 방식입니다.
짧게 “짝수로 맞춘다”로 기억하면 편합니다.
오사오십의 영어 표현은 Round, half to even (절반을 짝수쪽으로)라고 합니다. 금융권에서 많이 채택해서 쓰기 때문에 뱅커스 라운딩이라는 별칭으로 많이 불립니다. 이건 미국의 경우이고 한국 금융권에서도 이것을 채택해서 쓰는지는 모르겠습니다.
어쨌든 뱅커스라운딩으로 계산하면 다음과 같이 됩니다. 굵은 글씨 부분을 자세히 보세요.
0.4 반올림 하면 0 0.5 반올림 하면 0 <– 여기 0.6 반올림 하면 1 1.4 반올림 하면 1 1.5 반올림 하면 2 1.6 반올림 하면 2 2.4 반올림 하면 2 2.5 반올림 하면 2 <– 여기 2.6 반올림 하면 3 2.45 반올림 하면 2 <– 여기
숫자 몇개를 반올림해서 사사오입과 뱅커스라운딩 둘을 비교해보면 이렇습니다.
대상값 / 방식
사사오입
뱅커스 라운딩
0.4
0
0
0.5
1
0
1.4
1
1
1.5
2
2
1.6
2
2
2.4
2
2
2.5
3
2
2.6
3
3
4.5
5
4
4.4445
5
4
사사오입가 뱅커스라운딩의 비교표
뱅커스 라운딩은 미국 측정 계산의 표준이라고 알려져 있습니다. 직접 물어봐서 확인해 보지 않았지만 온라인 문서에 그렇게 적혀 있습니다. 그래서 최신의 컴퓨터 언어나 계산 관련 소프트웨어들에서 기본으로 지원하는 반올림 함수는 우리가 아는 사사오입 방식이 아닌 뱅커스 라운딩을 사용하는 것이 많습니다.
소프트웨어들이 여전히 미국산이 많기 때문인데 특히 과학계산 용도로 쓰는 것들이 그렇습니다.
반올림? 이라는 용어
사사오입은 엄밀히 말하면 반올림이 아닙니다. 우리가 쓰는 반올림은 영어로 round라고 하는데 round라고 하는 것의 원래 뜻은 숫자를 단순하게 만드는 것을 말합니다.
round 는 둥글게 심플하게 밋밋하게 한다는 뜻입니다.
그래서 “무조건 올림”은 영어로 round-up이라고 하고 “무조건 내림”은 영어로 round-down이라고 합니다. round라는 단어가 들어 있지만 “무조건 내림”과 “무조건 올림”은 반올림이 아닙니다. 반만 올리는 것이 아니라 그냥 올리고 내리는 것이지요.
그러니까 영어로 round라고 하는 것을 우리식으로 반올림이라고 표현하는 것은 맞지 않다라고 말씀하시는 분이 있는데 저도 그게 맞다고 생각합니다.
그리고 사사오입 반올림의 영문 표현이 away from zero인데 뜻을 보면 5를 0에서 멀어지게 하는 것이라서 반올림이라고 표현하는 것에 무리가 있다고 합니다. 반면 half to even 방식은 짝수방향으로 반을 올려주거나 절사하기 때문에 이것이 진짜 반올림 방식 중 하나입니다.
하지만 이미 관행으로 다들 사사오입을 반올림이라고 말하기 때문에 편의상 여기에서도 모두 합쳐서 다 “반올림”이라고 하겠습니다.
뱅커스 라운딩을 사용하는 이유
계산과정에서 반올림 때문에 발생하는 오차를 줄이기 위해서 고안된 것입니다. 반복계산을 하면서 반올림이 계속 반복되면 결국 오차를 만들게 되는데 반복 계산 후 최종 결과에서 이 반올림들에 의해 발생하는 오차를 줄이도록 하려는 것입니다.
지인 분이 알려주셨는데 해석학에서 이걸 증명하는 것이 나온답니다.
하지만 간단하게 설명하면 숫자 0과 1이 있습니다. 이 사이에 존재하는 소숫점 첫째자리까지의 수만 보면 다음과 같이 9개의 숫자가 있습니다. 10개가 아닙니다.
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
이 숫자들을 다 반올림한다고 할 때 0.5는 정확하게 한가운데 있기 때문에 절사해서 버릴 것인지 1로 올려줄 것인지가 고민이 됩니다. 그리고 어느쪽으로 하든 오차를 만듭니다.
사사오입 방식은 5를 항상 위로 올리기 때문(away from zero)에 여기서 숫자가 원래 올리지 않았을 때 보다 오차가 커지는 일이 많아집니다. 그리고 잘 생각해 보면 어딘가 공평하지 않은 구석이 있다는 것을 느낄 수 있습니다.
대신 뱅커스 라운딩처럼 짝수쪽으로 수렴하게 해서 조금은 더 공평해집니다. 그리고 이 방식이 오차가 덜 발생한다는 것은 오래전에 여러가지 방법과 실험을 통해 증명되었다고 합니다.
그 외의 반올림 방식
위키피디아의 rounding 페이지를 보면 반올림(rounding)방식이 상당히 많다는 것을 보고 놀랄 수 있습니다. 반올림 문제는 메소포타미아에도 기록이 남아 있는 오래된 문제라고 되어 있습니다. 그리고 뱅커스 라운딩이라고 불리는 half to even 방식은 1940년도 나온 것이라고 적혀 있습니다.
뱅커스 라운딩을 기본으로 채택해서 제공하는 컴퓨터 언어나 소프트웨어가 생각보다 좀 많습니다.
R, Python3과 같은 것들이 그렇습니다. 그 외의 랭귀지도 꽤 많습니다. Excel과 RDBMS 같은 소프트웨어의 반올림 함수는 대부분 우리가 아는 “사사오입”으로 되어 있습니다. 그러다보니 행수가 많은 데이터에서 나누기, 곱하기 같은 것들이 여러번 반복하고 그 결과를 모두 합한다거나 평균을 구한다거나 하면 동일한 데이터를 가지고 계산을 해도 사용하는 컴퓨터 언어나 툴에 따라 양쪽의 결과값에 미묘한 차이가 발생합니다.
즉, round함수의 방식이 다른 것을 각각 따로 어떤 데이터의 사칙 연산을 하면서 반올림이 섞인 계산을 반복하는 경우에는 양쪽에서 똑같이 계산해도 round의 방식으로 인해 서로 결과값이 안맞는 문제가 발생합니다. 이때 정합성 오류가 부동소숫점 연산 문제나 반올림 방식의 차이로 인한 문제라는 것을 알면 그것은 해결하기도 어렵고 원인을 알면 오차를 감수하고 넘어갈 수도 있지만, 그것을 모르면 오차가 어디서 발생했는지 원인를 찾기 위해서 시간을 허비하게 됩니다.
버그인지 계산을 잘못한 것인지…
그래서 차이가 있다는 것을 알고 있는 것이 좋습니다. 물론 뱅커스 라운딩을 기본으로 채택한 것들은 별도로 사사오입을 지원하는 함수를 따로 제공하는 것이 많습니다. (아닌 것도 있는데 그럴 때는 구현해야 합니다)
워드프레스 구텐베르크 편집기를 사용할 때 조금 손이 가지만 그래도 워드프레스의 설정에서 고난의 삽질을 하지 않고 간단하게 Mermaid를 사용하는 방법을 설명드리려고 합니다. 데이터사이언스와 관련없는 포스트는 이 블로그에는 잘 안쓰지만 일탈을 해봤습니다.
구텐베르크 Gutenberg
Mermaid를 워드프레스(WordPress)에서 사용하는 방법을 설명하기전에 구텐베르크 얘기를 먼저 해야 하겠습니다.
워드프레스가 글 편집기로 구텐베르크(Gutenberg)라는 것을 쓰도록 유도한지가 꽤 된 것 같습니다. 이 포스트를 쓰는 시점으로부터 수개월 전으로 기억합니다. 원래 구텐베르크가 워드프레스에 기본 패키지에 포함되어 있지는 않는 것 같은데 “편집기로 구텐베르크 써보지 않겠어?” 라는 식으로 관리자화면에서 자꾸 물어보길에 예전에 무심결에 눌러서 플러그인을 설치한 후에 제 블로그도 구텐베르크로 작성하고 있습니다. 그 뒤로는 전 너무 멀리 와버렸습니다. ‘ㅁ’;
구텐베르크는 포스트를 쓰면서 블럭 단위로 콘텐트를 나눠서 관리하고 편집하는 방식인데 위지윅(WYSIWYG)에 중점을 더 둔 편집방식입니다. 물론 그전 방식인 클래식 에디터를 같이 쓸 수 있습니다만 클래식 편집기로 작성한 글은 클래식편집기로만 열리고 구텐베르크로 작성한 것은 구텐베르크 편집기로 열립니다.
구텐베르크 편집기를 쓰면 편리한 점이 더 많아서 저는 구텐베르크를 주로 쓰고 있습니다. 구텐베르크라는 이름처럼 출판 편집을 위한 소프트웨어를 사용하는 기분이 듭니다.
구텐베르크는 사용하려면 적응기간이 조금 필요합니다. 버그도 아직 꽤 있습니다. 복잡한 구조의 포스팅을 안하시는 분들께는 좋겠고 복잡한 요소들이 잔뜩 있는 포스트를 장벽이 큽니다.
기존에 잘 쓰던 플러그인과 충돌을 하거나 작동이 안되는 부분도 꽤 많아서 플러그인을 별도로 찾아서 추가 설치해야 하거나 포기해야 하는 부분도 상당합니다. 그래서 클래식 편집기에서는 플러그인만 설치하거나 익숙하게 했던 작업도 구텐베르크를 쓰면서 부터는 많이 힘들어졌습니다.
워드프레스에 Mermaid.js 추가하기
워드프레스에 Mermaid.js를 사용하려면 Mermaid.js와 CSS하나만 추가해주면 됩니다. 그런데 이게 플러그인이 없으면 추가하기가 조금 곤란합니다. 현재까지 제대로 지원하는 플러그인은 못찾았고 functions.php를 수정하는 방법이 일반적인데 그렇게하고 싶지는 않았습니다. 저렇게 하면 워드프레스를 업그레이드하거나 테마를 바꾸거나 하면 난장판이 되었던 경험이 있습니다.
그래서 간단하게 붙이는 방법은 글편집에서 워드프레스 구텐베르크 타입에 HTML 요소라는 것이 있어서 블럭 유형을 HTML으로 바꾸고 다음과 같이 HTML 코드를 넣으면 됩니다.
<script src="https://unpkg.com/mermaid@8.0.0-rc.8/dist/mermaid.min.js"></script>
<link rel="stylesheet" href="https://cdn.rawgit.com/knsv/mermaid/0.5.6/dist/mermaid.css">
<script>
mermaid.initialize({
startOnLoad: true,
flowchart: { curve: 'basis' }
});
</script>
<code class="mermaid">
graph LR
M --> e
e --> r
r --> m
m --> a
a --> i
i --> d
</code>
소스 코드에서 js 파일의 링크과 css는 적당히 최신의 것으로 찾아서 바꾸시면 되고 Mermaid코드를 넣을 때 code 태그에 class를 mermaid로 지정하시는 부분이 핵심입니다. code 태그 대신 div나 pre 태그를 사용하면 “>” 기호와 다른 특수문자들을 인코딩(특수기호들을 &#으로 시작하는 코드로 바꾸는 것)하기 때문에 Mermaid.js가 다이어그램 문법을 해석하지 못해서 그림이 표현이 안됩니다. 현재 워드프레스에서는 code 태그의 안쪽은 HTML 인코딩을 하지 않습니다.
위의 소스코드에서 js와 css 파일을 인클루드하는 것은 따로 보관해 두거나 전에 작성했던 포스트에서 복사해서 붙이기는 방법을 쓰고 Mermaid 코드 부분만 따로 작성해서 code 태그 안쪽에 붙여 넣으면 Mermaid 다이어그램을 붙여 넣을 수 있습니다.