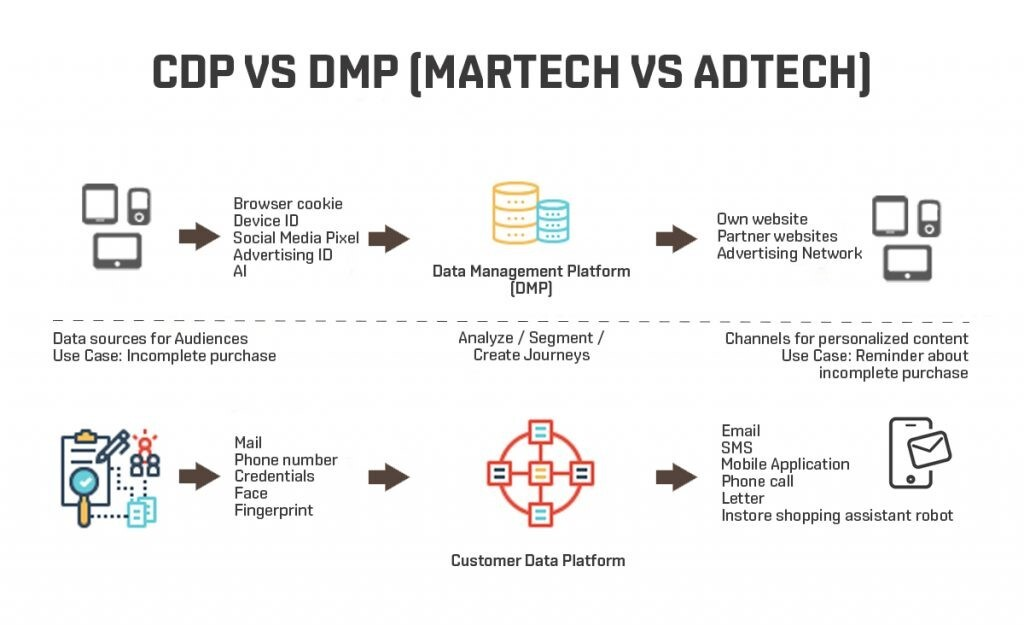
게임 광고에 대한 분석을 하다 보면 종종 재밌는 사실을 알 수 있습니다.
그 중에 재밌는 것은 게임 내에서의 게임 광고입니다.
게임 내에 다른 게임 광고
모바일 게임을 설치해서 하다보면 아이템을 얻거나 다시시도를 하는 댓가로 광고를 보게하는 것이 많다. 광고 수익을 얻기 위한 것인데 게임 광고에서는 유난히 다른 게임의 광고가 많이 나옵니다.
이것은 예전에는 카니발라이제이션이라는 문제라 하지 않았던 것입니다. 즉 다른 게임의 광고를하면 사용자가 그 게임을 설치해서 하게 되고 지금 하는 게임은 하지 않기 때문입니다.
하지만 그럼에도 불구하고 최근 게임광고가 게임에 많이 보이는 이유는 다음과 같습니다.
모바일 게임에서 모바일 게임 광고가 많이 나오는 이유
- 게임은 원래 하던 사람이 하기 때문에
- 이 사람들은 하던 게임이 지루하면 새 게임을 깔아서 할 것이 분명하기 때문에
- 최근 게임들은 쉽게 질리는 것이 많고 게임 유저들이 콘텐츠 소비 속도가 매우 빠른 것이 특징
- 이렇게 해서 클릭 수익을 얻는다면 그게 게임을 계속하게해서 아이템을 판매해서 얻는 것보다 수익이 더 낫기 때문
- 어차피 모든 사용자는 언젠가는 게임을 그만할 것이기 때문에 고객 리텐션을 크게 생각하지 않고 광고를 하게 만드는 전략
※ 현재 설치된 앱은 모바일 사용자의 특성을 나타낸다.
- 게임 앱을 설치해서 게임을 많이 하는 사람은 게임을 또 설치할 가능성이 높다. 따라서 게임 앱에 다른 게임 광고를 하는 것은 매우 효과적이다.
- 이커머스의 버티컬 상품도 마찬가지다. 고기를 판매하고 싶으면 육류 앱이나 신선식품 앱에 광고를 하는 것이 효율이 가장 좋다. 그들은 이미 육류나 신선식품에 대해 매우 관심이 많고 적극적이기 때문이다.
같은 카테고리의 앱에서 같은 카테고리의 상품 광고를 하는 것은 매우 효과적이 수 있다
나이키 의류 앱이 있다면 현실적으로는 어려울 수 있겠지만 여기에서 아디다스나 다른 스포츠웨어 광고를 한다면 매우 클릭율이 높을 수 있습니다.
이런 것을 이용해서 많은 버티컬 이커머스(특정 카테고리만 판매하는 쇼핑몰)나 종합 이커머스에서는 메타 쇼핑이라는 것을 하려고 비즈니스 전환을 많이 하고 있습니다.
즉 메타쇼핑같은 곳에서 어떤 카테고리 또는 여러 카테고리의 상품을 모아서 추천시스템 같은 것을 해서 잘 보여주고 광고를 한다면 일반 광고 매체보다 클릭율과 구매율이 더 높아질 가능성이 매우 큰 것입니다.
이것은 이미 메타쇼핑 또는 버티컬 쇼핑에 자주 접속하는 사용자라면 적극적으로 제품을 구매할 의향이 있다는 것이며 구매에 적극적이기 때문에 정보를 얻기 위해서 클릭에도 적극적입니다.
카니발라이제이션은 어떻게 피하나?
예를 들면 특정 육류 판매 쇼핑 앱에서 타사의 육류 상품을 판매한다면 자사의 육류가 판매되지 않을 것이기 때문에 문제가 됩니다.
이 문제를 해결하는 방법은 매우 간단합니다.
회사를 여러 개 설립해서 만든 후에 브랜드와 상표를 다르게 하고 동일한 육류를 판매하는 것입니다.
일종의 트릭이지만 잘 알려진 예로 음식배달이 있습니다.
음식배달에도 많이 사용하는 방법으로 같은 업소가 여러 음식을 다른 상호로 배달앱에 등록하는 경우입니다. 이렇게 하면 음식업체에서는 전화를 받을 화률이 매우 높아 집니다. 물론 배달앱의 검색에서 상위에 나오게 하기 위해서 광고비, 홍보비가 많이 드는 것은 별개의 문제입니다.