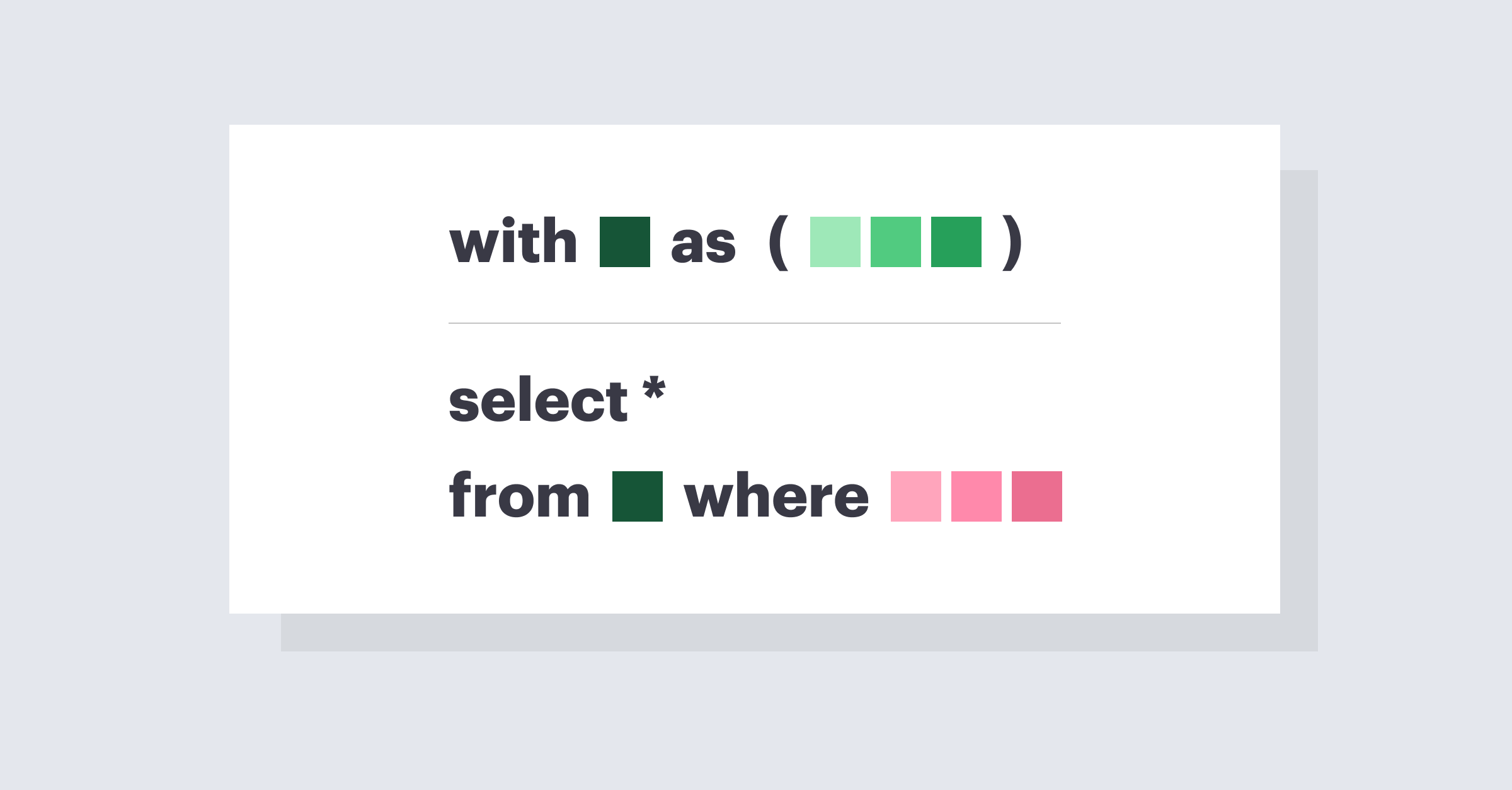
BigQuery로 Consine similarity를 계산해서 KNN 최근접 이웃을 계산하는 예제 코드입니다.
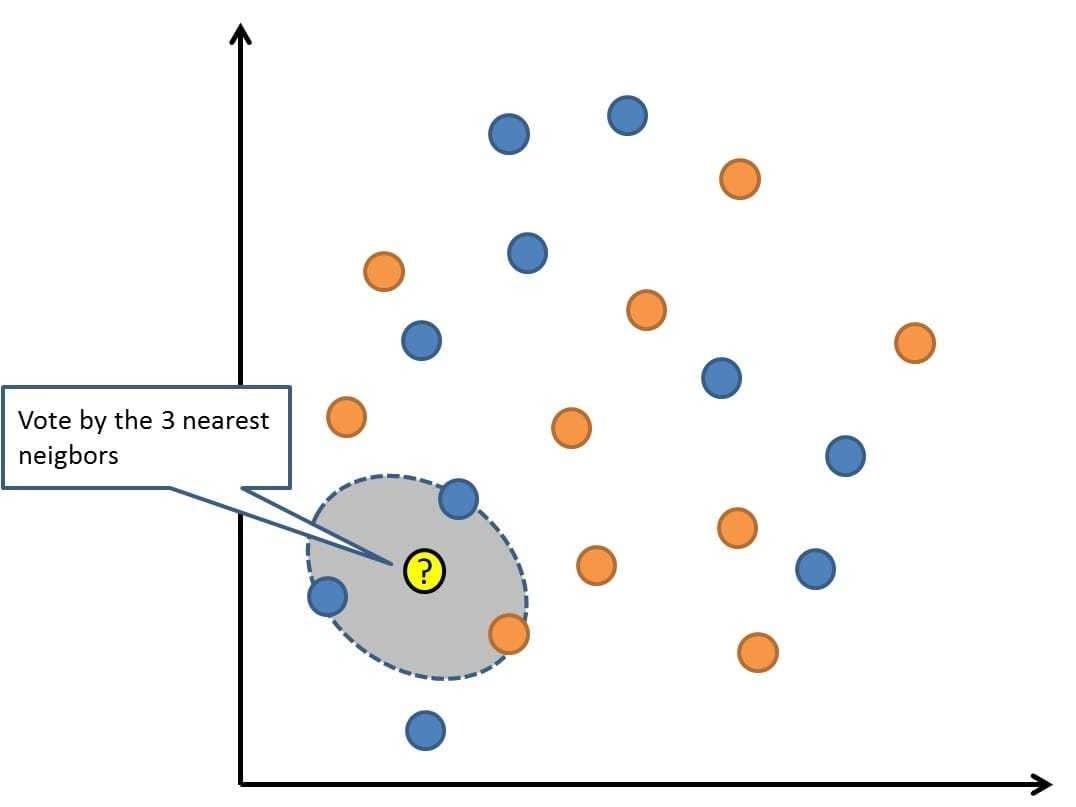
KNN = K Nearest Neighbor = 최근접 이웃
최근접 이웃은 기계학습에서 매우 오래된 기법입니다. 간단하지만 매우 정확한 시스템이지만 데이터프로세싱에 많은 자원이 소모되기 때문에 잘 사용되지는 않습니다.
Cosine Distance함수는 BigQuery에서 빠른 것을 제공을 해주기 때문에 따로 만들지 않고 제공하는 것을 그냥 쓰면 됩니다.
하지만 결국 BigQuery를 쓴다 해도 cross join을 해야합니다.
아무리 빅쿼리라고 해도 처리하는 데이터가 조금만 커도 cross join은 잘 실행되지 않습니다.
그래서 빅쿼리로 하는 KNN은 실용성이 있다고 보기는 어렵습니다.
작은 데이터에 대해서만 가능하기 때문에 그 점을 참고하시기 바랍니다.
WITH tbl_left AS (SELECT group_id, word AS word1, vector AS vector1
FROM recsys.recsys_word2vec
WHERE _PARTITIONTIME IS NOT NULL
AND group_id = '12345'
)
, tbl_right AS (SELECT group_id, word AS word2, vector AS vector2
FROM recsys.recsys_word2vec
WHERE _PARTITIONTIME IS NOT NULL
AND group_id = '12345'
)
select a.group_id, a.word1
, ARRAY_AGG(b.word2 ORDER BY ML.DISTANCE(a.vector1, b.vector2, 'COSINE') DESC LIMIT 50) as nn50
FROM tbl_left a
JOIN tbl_right b
ON a.group_id = b.group_id AND a.word1 != b.word2
GROUP BY a.group_id, a.word1
;