Interpolation methods (내간법)
용어 확인을 위해서 영어사전을 찾아 보시면 내간법/내삽법/보간법이라고 나옵니다. 뭔가 다소 괴기스러운 어감인데 (^^;) 보신적이 없다면 어감상으로는 뭔가 내부에서 간섭을 하거나 삽입하는 어떤것들이 연상될 것 같습니다.
내삽법 관련된 알고리즘을 찾다가 다시 당분간 이쪽분야를 할 일이 없어질 것 같아서 전에 찾아놓은 자료를 우선 아는데까지만 적어 놓으려고 합니다.
그래서 그냥 찾아 놓은 기법들 소개 정도입니다.
Interpolation(내간법)이라는 용어를 흔히 볼 수 있는 곳은
-
스크립트 랭귀지같은 것들중에 변수명을 문자열에 삽입해서 대치시키는 것.
이것은 coercing 이라고도 하는데 용어가 좀 다양하게 쓰입니다. “blah $varialbe blah” 요런거입니다. PHP, Perl등의 언어에서 쉽게 볼 수 있는데 별로 중요하지 않습니다.
-
데이터 분석에서 관측되지 않은 지점의 데이터를 추정하는 방법
당연히 이 포스트에서는 두번째입니다.
(아래 플롯 참조)
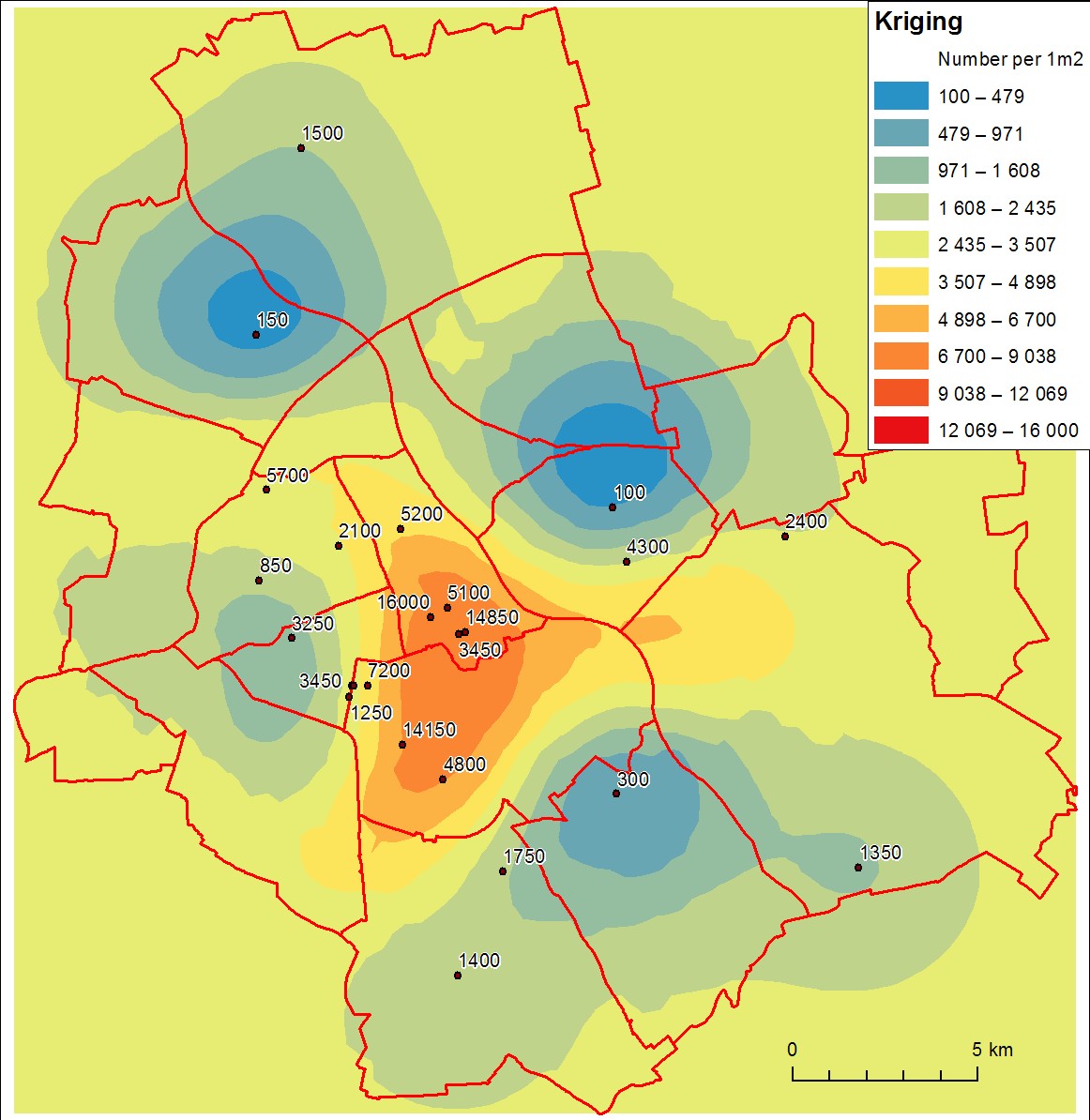
내간법은 관측치(Observation)가 없는 부분의 데이터를 관측치(Observation)를 이용해서 얼추 추정해서 때려 맞추는 것인데요. 대부분 현실적으로 관측을 모두 다 할 수 없어 중요한 부분만 관측하고 나머지는 추정을 해야 하는 경우에 쓰입니다.
세상은 우리의 상상만큼 그렇게 만만하지 않은 것 같아요. ^^
보통 공간통계(Geo-Spatial Analysis) 분야에서 쉽게 찾아 볼 수 있는데요.
활용에 대한 대략적인 예시는 이런 것들입니다.
-
전국의 모든 지점의 온도나 습도, 공기오염도 등을 다 측정할 수 없으므로 적당히 중간중간 중요한 지점을 측정하고 나머지는 보정해서 때려 맞출때
-
제조업등에서 불량 검사를 할 때 특정 판에서 온도 측정을 모두 할 수 없으므로 군데군데 하고 빈곳은 추정할 때
-
최근에는 IoT 스마트헬스케어 같은 곳에서 건물이나 집안의 온도나 습도에 대한 분포를 알고 싶은데 바닥에 센서를 죄다 깔아 놓을 수 없으니 적당한 곳만 측정하고 나머지는 때려 맞출때도 사용합니다.
사실 이것 때문에 살펴보게 된 것입니다만 그래서 어떤 방법들이 있나 봤더니 굉장히 많더군요
Regression Model (회귀 모델)
회귀 모델도 내간법에 들어갑니다.
생각해보니 그러네요. 회귀 모델도 결국 관측치도 미관측 데이터를 추정하는 것이니 그쪽으로 보면 그 분류가 맞습니다. 단 공간분석에는 적합하지 않으니 쓰지 말라는 말도 있습니다. (물론 쓰는 사람들도 있습니다)
Kernel Density Estimation (커널밀도추정)
패턴 인식이나 기계 학습 책을 보셨거나 관련된 일을 하신다면 커브피팅(curve-fitting)이나 커널밀도추정에 대해서 보신적이 있을 텐데요.
이것도 내간법으로 넣습니다.
커널 밀도 추정은 다차원 공간에서 씨알(데이터)을 하나 이상 머금은 다차원 깍두기(커널)를 만들고 깍두기를 스무딩해서 매끄럽게 만들어 밀도를 추정하는 방법입니다.
보통 2차원, 3차원까지를 많이합니다. 히스토그램의 구체화된 형태라고 할 수 있습니다. 공간 분석에서도 사용하긴 하지만 많이 사용하지는 않는 것 같습니다.
Inverse Distance Weighted Interpolation
해석을 하면 많이 어색하지만 역거리내삽법 또는 거리 반비례 가중치 내삽법등으로 바꿀 수 있을텐데 보통 IDW라고 통칭합니다. GIS나 Geo-Spatial에서 흔히 볼 수 있는 내삽법입니다. 그냥 거리가 멀어질 수록 영향을 덜 받는다입니다.
Kriging (그리깅 격자법)
만든 사람이 이름이 Krige여서 Kriging라고 합니다. 크리깅 또는 그리깅이라고 읽는데 우리말의 김치의 ㄱ과 같은 발음인 것 같습니다. 이름도 이상하지만 이건 상당히 복잡한데요. Spatial Analysis 책을 들여다보면 분산도(Variogram) 부터 공간자기상관(Spatial Autocorrelation) 같은 말부터 Semivariogram같은 비전문가에게는 무척 생소한 용어가 나오고 알고리즘을 따라 내려가다보면 결국 최적화 문제로 라그랑지 승법이 나옵니다.
성능이 굉장히 좋다고 알려져 있어서 대부분 GIS나 Geo-Spatial에서는 항상 언급이 됩니다. IDW보다는 수학적, 통계학적으로 기반 이론이 훨씬 그럴싸하기 때문에 굉장히 자주 사용하는데 역시 좋은 만큼 안쪽은 쉽게 설명하기에는 상당히 복잡합니다.
그리고 크리깅은 다시 Simple Kriging, Universal Kriging, Ordinary Kriging 등으로 나뉩니다.
보간법 중에는 Kriging이 끝판왕쯤 되는 것 같습니다. 추가로 크리깅은 예측값에 대한 에러를 추정하는 것이 가능하다고 되어 있습니다.
조금 신기하네요. 요건 나중에 따로 정리를 시도해 보겠습니다. (너무 어려워서…)
보간법은 이외에도 무수히 많습니다. K-NN도 사용을 하구요 당췌 뭐가 뭔지 모를 정도로 많아서 혼란스러운데 역시 가끔은 다른 쪽에서는 뭘하고 있는지 살펴보는 것도 중요한 것 같습니다.