
라마의 변천사를 보여주는 인포그래픽스입니다. 불과 1년만에 이런 규모가 된 것은 놀랍습니다.
글쓰는 시점에 405B는 아직 나오지 않았지만 정말 기대됩니다.
라마의 변천사를 보여주는 인포그래픽스입니다. 불과 1년만에 이런 규모가 된 것은 놀랍습니다.
글쓰는 시점에 405B는 아직 나오지 않았지만 정말 기대됩니다.

iPhone에서 Llama3 8B 모델을 구동시키는데 성공했다는 뉴스가 나오자마자 인터넷 곳곳에서 따라하기에 성공사례가 연달아 나오고 있습니다.
정리하자면
애플 실리콘은 애플이 독자적으로 만든 반도체입니다. 그래서 인텔, AMD의 프로세서와 Nvidia GPU용으로 만들어진 모델이 그냥 작동하지 않습니다. Llama3도 마찬가지입니다. 돌아간다고 하더라도 효율이 문제인데 그래서 애플은 애플 실리콘에서 작동하는 자체 고속행렬연산 프레임워크인 MLX라는 것을 만들었습니다.
Llama3를 애플의 아이폰, 아이패드에서 돌리려면 MLX에서 돌도록 해야 제대로 되는데 그걸 매우 쉽게 했다는 것입니다.
아이폰 다음 모델에는 거의 온디비이스 AI 탑재될 것이 분명합니다.
온디바이스AI는 디바이스내에서 외부 통신없이 자체 능력만으로도 AI 프로세싱을 처리할 수 있는 것을 말합니다.
세상이 바뀌는 순간이 매우 빠르게 오고 있다는 느낌이 듭니다.
다음은 Llama3 8B를 iPhone 15 Pro Max에 설치하는 방법입니다. 편의상 영문 그대로 올립니다.
UPDATE: Successfully ran Llama3 8B Instruct on iPhone 15 Pro Max
Steps:
1. Install LLM Farm
2. Download Llama3 8B Instruct GGUF from Huggingface
3. Import & Run the model in LLM Farm
LLM Farm: https://llmfarm.site
Model File: https://huggingface.co/FaradayDotDev/llama-3-8b-Instruct-GGUF… Detailed steps coming soon!
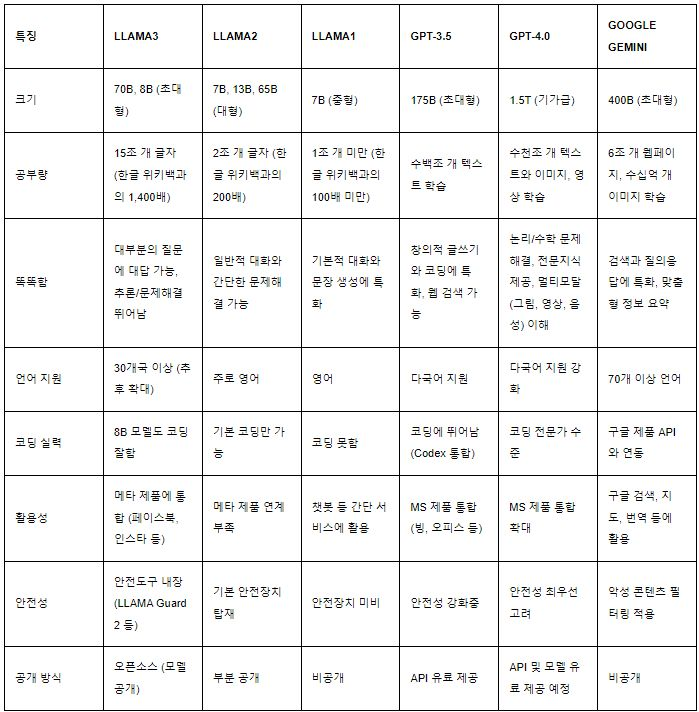
스펙과 성능에 대한 비교표입니다.
전반적으로 GPT-4가 가장 성능은 뛰어난 것으로 평가 받고 있습니다.
비용효율과 사용성 측면을 고려하면 성능을 조금 포기하고 모델의 크기와 같은 하드웨어적 특징을 고민해야 하기때문에 용도에 맞는 것을 선택해야 하겠습니다.
아무리 GPT가 성능이 좋아도 오픈소스경량 LLM인 Llama3의 매력을 무시하기는 어려울 것 같습니다.
놀라운 모델이 또 발표되었습니다.
마이크로소프트가 사진 한장만 있으면 사진속 인물이 말을 하거나 노래를 부르는 영상으로 만들어주는 AI모델을 발표했습니다.
아래 링크에 들어가서 데모를 보시면 됩니다.

할루시네이션은 언어 AI 모델(LLM)이 사실이 아닌 엉뚱한 소리를 사실 처럼 확증적으로 말하는 것을 말합니다.
할루시네이션(Hallucination)은 거짓말과는 다른데 거짓말은 의도적으로 진실을 말하지 않고 다르게 말하는 것인지만 AI는 진실과 거짓을 구별하지 못하고 의식이 없기 때문에 의도라는 것 자체도 없습니다.
그래서 틀린 사실도 매우 당연하다는 듯이 사실처럼 생성하기도 합니다. 그런데 AI가 생성한 텍스트가 진실인지 아닌지 알아차릴 수 있는 지식이 없다면 AI의 거짓을 착각해서 믿게 됩니다.
LLM 의 구조적인 특징으로 인해 할루시네이션은 AI모델 자체로는 완벽하게 극복이 안됩니다. 나중에 개선된 모델이나 다른 방법이 나온다면 가능하겠지만 지금은 아닙니다.
LLM의 작동방식은 확률적으로 입력한 단어의 다음 단어가 나올 것을 예측하고 그것을 매우 긴 단어의 연결에 대해 연속적으로 행하는 모델이기 때문입니다. 깊은 고찰이나 인과적 사실 검증, 사실 의심 같은 인간의 고급 사고 능력이 LLM에게 없기때문입니다.
그리고 인간도 할루시네이션이 있습니다. 잘못 알고 있는 것을 잘 알고 있다고 착각하고 우기는 것 말입니다. 하지만 인간은 자신이 틀렸을지도 모른다는 의심 또한 하기 때문에 현명한 사람들은 할루시네이션이 거의 없습니다.
학습량을 마구 늘리면 할루시네이션이 극복되지만 얼마까지 늘려야 눈치채지 못할 만큼 줄어드는지는 알 수 없습니다.
현재 LLM의 할루시네이션을 극복하는 거의 유일한 방법은 RAG (Retrieval Augmented Generation)을 사용하는 것입니다.
RAG는 AI가 대답할 때 질문과 관련이 있는 자료를 찾아서 참고해서 대답하게 만드는 방법입니다.
간단하게 말하면 AI가 대답하기 전에 벡터데이터베이스를 뒤져서 자료를 찾은 다음에 대답할 때 참고하도록 합니다. 당연히 벡터DB에는 사실만 저장되어 있어야 합니다.
RAG에서 사용하는 DB또는 검색엔진 꼭 벡터 기반일 필요는 없습니다. 텍스트기반의 검색엔진인 엘라스틱 등을 사용해도 되고 DB를 사용해도 됩니다. 벡터 기반을 사용하는 이유는 벡터기반이 렉시컬 기반이 아닌 컨텍스트 기반으로 매치가 가능하기 때문입니다. 전통적인 검색엔진이나 DB는 단어들이 얼마나 일치하는지를 찾는 방법으로 쓰지만 벡터 기반은 의미가 비슷한지를 확인하는 구조로 되어 있습니다.
ASI모델을 사용할 때 RAG로 해결해야 하는 문제는 프롬프트와 관련이 있는 또는 챗봇의 경우 사용자가 질의한 것가 관련이 있는 것만 잘 추출해서 지시어로 넣어주어야 한다는 것입니다.
잘못된 검색 결과는 의미가 일치하지 않는 콘텐츠를 지시어로 넣어주면 할루시네이션이 생기거나 조금 엉성하고 엉뚱한 답을 하게 됩니다.
다른 구조의 모델이 나오거나 파인튜닝을 엄청나게 많이 하지 않으면 RAG외에는 할루시네이션을 없애는 방법은 없습니다.
RAG를 위해서 필요한 것
여기서 가장 중요한 것은 2번입니다. RAG가 적용된 모델은 없어도 지시어로 충분히 해결할 수 있지만 있다면 더 매끄러운 결과를 보여줍니다.
청킹은 매우 중요한 기술인데 콘텐츠를 어떻게 잘라서 검색엔진에 추가할지에 대한 방법입니다. RAG에서 가장 중요한 노하우라고 할 수 있습니다.
좋은 방법은 잘 알려지지 않고 각 기업의 내부에서만 사용되고 있습니다. OpenAI도 RAG를 지원하지만 어떤 방법으로 청킹을 하는지에 대해서는 오픈하고 있지 않습니다.
AI모델을 실시간으로 빌드할 수 있는 방법은 없습니다. 모델을 만드는데 계산양이 매우 많기 때문입니다. 최신 지식을 인간처럼 곧바로 업데이트하지 못합니다.
유일한 방법은 어디선가 사실을 가져와서 모델내에 실시간으로 넣어주는 방법뿐입니다.
그래서 당분간은 RAG가 중요하게 쓰일 수 밖에 없습니다.