페이스북과 인스타그램의 주 수익은 광고수입입니다. 광고 수익을 내기 위해서는 사용자의 트래킹 정보가 필요한데 이것은 웹브라우저는 쿠키, 안드로이드앱은 ADID, 애플 IOS는 IDFA를 사용합니다.
웹브라우저의 쿠키로 사용자의 트래킹 정보를 제고하는 것을 3rd party cookie 제3자쿠키라고 합니다. 이 제3자 쿠키를 이용하면 사용자의 트래킹 정보를 페이스북 외부와 내부에 연동해서 추적할 수 있습니다.
사용자가 쇼핑몰에서 본 노트북이 있다면 페이스북에 접속했을 때 그 노트북이 광고로 보이거나 하는 것입니다.
그런데 이게 3자 쿠키와 사용자 트레이싱이 점진적으로 사라지게 되는데 제3자 쿠키는 2023년 말로 크롭라우저에서 차단됩니다. 페이스북에서는 이걸로 인해 광고 노출을 하는 큰 수입이 사라지게 되므로 다른 대안을 찾아야 하는데 그건 사용자의 행적정보를 광고주에게 제공하는 것입니다.
해주면 어떤 일이 일어나는데?
그전에도 이런것을 어느정도 했었지만 정보제공동의 서명을방고 난 후에는 법적인 문제없이 본격저으로 할 수 있고 제3자쿠키나 ADID를 통한 사용자 트래킹이 사라지면서 손실이 발생하는 광고 수익을 대체할 수 있게 됩니다.
즉, 본인의 행적과 일부 데모그래픽 정보를 외부에 제공하고 어떤 형태로 그 댓가를 얻을 수 있게됩니다. 그렇다고 해서 주민등록번호깥은 것이 유출되거나 하지는 않지만 사는 지역, 성별, 연령대, 가입한 그룹들을 통한 성향, 취미, 친구관계를 통한 사회적 지위, 직장, 소득, 쓰는 글 등을 이용한 성향 분석 등으로 정리한 정보를 광고주에게 제공할 가능성이 큽니다.
페이스북 쿠키를 차단하고 ADID를 리셋하면 되는거 아닌가?
페이스북에 로그인한 정보를 사용하기 때문에 쿠키를 차단하는 것과 상관없이 정보는 제공됩니다.
인스타그램도 동일합니다. 즉 트래킹 당한 정보를 제공하지 않고 싶으면 페이서북과 인스타그램에 로그인하지 않으면 됩니다.
페이스북, 인스타그램은 쓰면서 정보를 추적당하지 않는 방법은 없는가?
없습니다. 매체 또는 플랫폼을 쓰는 댓가로 행적 정보를 제공하는 것이고 그걸 기반으로 광고 수익을 얻는 것입니다. 플랫폼에서 광고를 보고 싶지 않거나 추적하는 것을 피하려면 그 플랫폼을 쓰지 않아야 합니다.
이런 구조는 구글, 네이버, 카카오 다음 모두 같습니다. 이들 모두 정보를 수집하고 있고 광고에 이용하고 있습니다. 추적당하지 않으려면 로그인하지 않으면 됩니다. 그럴 수 있다면 말이죠.
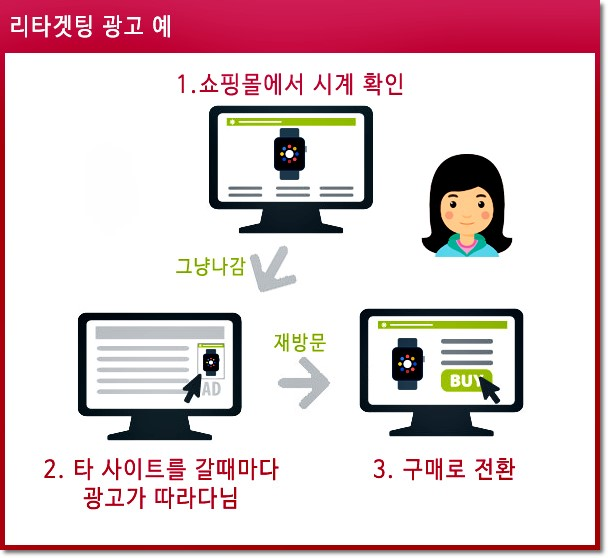
온라인 광고 기법 중에 리타겟팅(ReTargeting)이라는 것이 있습니다. 움직이는 타겟을 따라다닌다는 말인데 여기서 타겟은 인터넷 사용자를 말합니다.
자신이 한 번 본적이 있는 상품에 대한 광고를 계속해서 보여주는 광고입니다. 한 번 쯤은 목격했을 것입니다. 이거 신기해 보일 수 있지만 실상은 매우 간단한 것입니다.
어떻게 내가 봤던 물건을 나에게 다시 광고하는가?
간단하게 쿠키를 사용합니다. 제3자쿠키(3rd party cookie)라고 합니다.
예를 들어 웹브라우저로 A라는 회사의 노트북에 대한 정보를 접속해서 본다고 가정하겠습니다.
1. 웹브라우저로 그 상품에 대한 정보가 있는 페이지에서 광고회사(제3자)의 자바스크립트를 호출해서 사용자가 어떤 상품을 보고 있는지 누구인지 등의 정보를 넘겨주고 동시에 광고회사에서는 사용자의 브라우저에 식별이 가능하도록 쿠키를 심어 놓습니다. 이 때 광고회사는 여러군데일 수 있습니다. 동시에 한군데 일 수도 있고 10군데 일 수도 있습니다.
2. 사용자가 다른 웹사이트인 뉴스, 블로그, 커뮤니티 등에 접속하면 그 사이트들은 광고회사와 제휴를 하고 있을 수 있는데 구글, 페이스북, 네이버, 다음 그리고 특정 광고회사와 직접할 수도 있습니다.
이때 구글과 다음 등은 다른 회사에게 다시 광고를 또 중계해 주는 방식을 할 수도 있고 직접 광고를 할 수도 있습니다. 이간 복잡하니 지금은 설명을 건너 뜁니다.
어쨌든 광고를 제공할 수 있는 회사 중에 아까 1에서 쿠키를 심어 놓은 회사중 하나 또는 여럿이 있고 이 회사들이 광고를 내보내겠다고 응답한다면 그때 이 회사들은 사용자가 봤던 상품의 배너이미지를 화면에 보여줍니다.
이것이 리타겟팅입니다.
모바일에도 그러던데 대체 어떻게 하는 것일까?
모바일 윕브라우저를 사용한다면 동일한 방식을 씁니다. 모바일앱인 게임이나 다른애플리케이션에서 보이는 것은 ADID 또는 IDFA라는 스마트폰에 기록되어 있는 임의식별코드를 이용합니다. 이 코드는 스마트폰에 자동으로 부착되는데 변경하거나 막도록 설정할 수 있습니다.
원리는 쿠키와 동일한데 이 아이디를 블럭하면 아무 광고나 보이게 됩니다.
가는 곳마다 계속 따라다니는 것은 어떻게 하는 것일까?
광고회사는 여러 매체와 제휴를 맺습니다. 즉 여러분이 다니는 유명한 사이트들이 많은 광고회사와 제휴를 하고 있고 많은 광고회사에게 접속 정보가 전달됩니다. 가는 곳마다 따라다니는 것 처럼 보이는 것입니다. 하지만 외부 광고회사와 제휴를 하지 않은 사이트도 있기 때문에 그런 사이트에서는 적어도 따라다니는 광고는 보이지 않습니다.
막으려면 어떻게 하면 될까?
브라우저를 시크릿모드로 사용하거나 쿠키를 블럭시키는 보안 브라우저를 사용하면 따라다니는 광고는 잘 나오지 않습니다. 하지만 그 자리에 전혀 관련없는 엉뚱한 광고가 보이게 됩니다.
따라다니는 광고인 리타겟팅 광고가 보이지 않을 뿐이지 다른 기법의 광고나 무작위 광고는 여전히 보여집니다.
광고를 완전히 안보이게 할 수는 없을까?
광고를 불록하는 확장소프트웨어를 사용하면 되지만 완벽하게 막지 못하고 특정 사이트는 광고를 차단하는 경우 내용물이 안보이도록 해놓기도 합니다.
내 개인정보와 행적이 다 노출될까?
노출 안됩니다. 업체들끼리 데이터를 익명화하거나 그룹화해서 숨기도록 강제되어 있습니다.
개연의 행적을 알아내거나 개인정보를 알아내려면 업체들끼리 한통속으로 짬짜미를 해야 하는데 그러기가 어렵고 금융사, 포털사, 광고사, 매체 등이 일심 동체가 되어서 서로 정보를 교환하거나 제공해야 하는데 현실적으로 그렇게 못합니다.
행여 했다가 걸리면 정부의 처벌이 강력하며 작은 회사는 멸망하게 됩니다. 그래서 안합니다.
그리고 개인정보, 개인행적추적 등에 대한 규제가 점점 심해지고 있고 3rd cookie와 ADID는 이제 사라지게 될 운명입니다.
제3자 쿠키를 막을 수 없는가?
Mac/IOS의 사파리 브라우저에서는 이미 막혀 있습니다. 크롬과 크롬기반의 브라우저는 2023년 12월 31일 기점으로 제3자 쿠키를 쓸 수 없게 됩니다.
안드로이드의 ADID는 조만간 기본 설정이 정보제공이 자동 허용에서 비허용으로 변경될 예정입니다.
시스템 만들기와 기술적인 숙제
리타겟팅을 하기위한 기본 설계는 간단합니다. 리타겟팅의 문제는 비즈니스적인 문제와 서버비용입니다.
사용자의 universal id를 관리해야 하기 때문에 key-value NoSQL이 있어야 합니다.
나머지 부속 시스템은 살을 붙이면 됩니다.
트래킹태그와 광고송출은 견고한 자바스크립트를 작성해서 각각 심어두면 됩니다.
트래킹태그 호출과 광고호출을 받아줄 대몬을 각각 만들어야 하는데 AWS lamda같은 것을 쓸 수 있겠지만 네트워크나 비용문제로 인해 자체 서버로 구축합니다.
C++, Java, GoLang, Rust 등을 이용해서 만들면 됩니다.
왜 쉽게 못하는가?
위와 같이 하면 되지만 말은 간단하지만 시스템은 실상 살을 붙이고 고가용성 등을 보장하려면 많은 삽질이 필요합니다. 게다가 앞서 비즈니스적인 문제를 말했는데 매체와 광고주가 각각 자기 사이트에 Javascript 코드를를 심어줘야 하는 문제가 있습니다.
대량의 트래픽
수만개의 매체와 수만개의 광고주, 수천만개의 상품이 있다고 할 때 이 트래픽을 모두 처리하는 것도 숙제입니다. 트래픽을 받아줄 서버와 데이터를 저장할 빅데이터 처리를 위한 스토리지와 서버버가 필요합니다. 배보다 배꼽이 큽니다.
어떤 광고를 보여줄 것인가?
사용자가 가장 최근에 본 제품들. 그러니까 약 24사긴 이내에 여러 제품을 사용자가 살펴봐고 그 내역이 NoSQL에 기록되어 있다고 할 때 그 중에 어떤 것을 보여줄 것인가 하는 것입니다.
그냥 간단하게 가장 최근에 본 것을 보여주면 되겠지 싶지만 실상은 그렇지 않습니다. 어떤 상품의 광고를 보여주며 그 광고를 클릭하고 물건을 결국 사고야말지는 상황에 따라 사람에 따라 제품에 따라 제품 종류에 따라 브랜드에 따라 모두 각기 다릅니다. 이걸 잘 선택하는 것이 기술입니다.