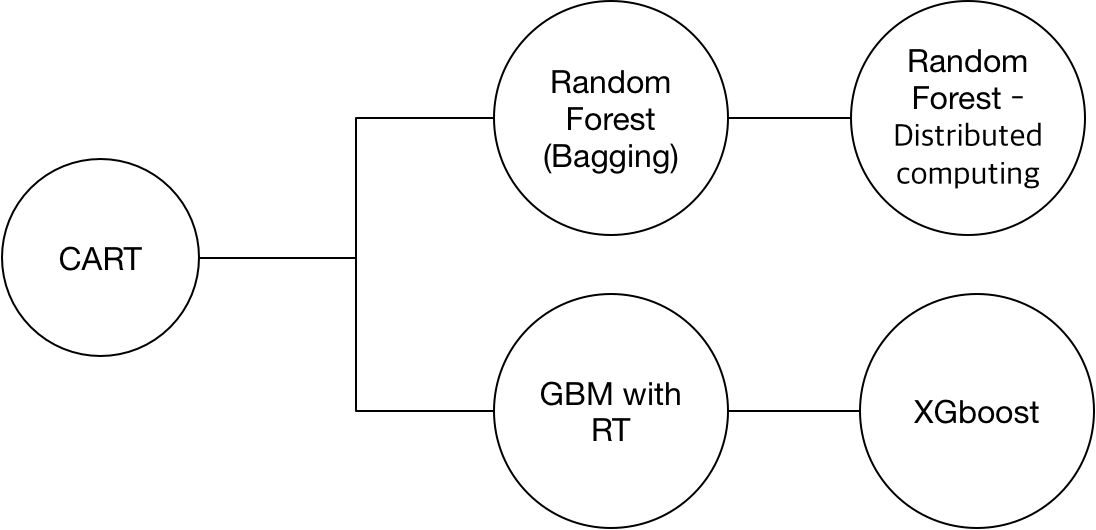
광고 캠페인을 운영하다보면 비슷한 또는 동일한 캠페인인데 매체 또는 DSP업체 성과가 다음과 같이 다른 경우가 있습니다.
- CTR은 높지만 CVR이 낮은 것
- CVR은 높지만 CTR이 낮은 것
CTR과 CVR은 단순하게는 DSP의 타겟팅 능력과 매체의 품질에 가장 큰 영향을 받습니다만
그럼에도 불구하고 둘 중 어느 것이 좋은가를 기술적으로 볼 때
- 광고업체(매체와 DSP모두)의 입장에서는 1번이 좋습니다.
- 광고주의 입장에서는 2번이 좋습니다.
아직도 광고비 과금을 CPC(클릭당 과금) 방식으로 많이하기 때문입니다. 클릭율이 높으면 과금율이 높아지므로 매체( CPC매체인 경우)와 광고회사에게 좋습니다.
하지만 여기에 생각할 부분이 더 있습니다.
CPC가 만약 가변인 경우입니다. 즉 몇몇 광고 업체처럼 가변 CPC로 KPI에 따라 목표치에 최대한 근접하게 광고를 운영한다고 하면 생각할 것이 많아집니다.
CTR이 낮아도 광고요금이 상대적으로 높을 수 있고 CTR이 높아도 광고요금이 낮을 수 있습니다. 즉 CTR만으로는 광고의 성과를 정확하게 알아낼 수 없습니다.
결국 cVR로 마찬가지가 됩니다. 클릭 후에 오디언스의 액션에 따라 전환되는 비율을 측정하는데 CVR이 조금 낮더라도 전환수가 많다면 CVR이 높아도 전환수가 많지 않은 것 보다는 좋습니다.
CPC가 만약 고정이라면
그래도 CTR이 높은 경우가 사실은 더 유리합니다.
CVR은 원래 CTR보다 높게 형성되지만 보통 물건의 품질, 가격경쟁력, 브랜드파워에 따라 달라집니다. 그럼에도 불구하고 cTR이 높아져서 전환수가 많아지는 것이 전환률이 높은 것보다는 광구주 측이의 매출이나 이윤이장에서는 유리합니다.
결론
많은 경우에 CTR이 높고 CVR이 낮은 것이 더 좋습니다. 그 반데의 케이스보다는 유리합니다. 하지만 항상 그런 것은 아닙니다.