은전한닢으로 텍스트마이닝, 자연어처리를 하거나 은전한닢에 의존성이 있는 소스코드, 패키지를 쓰려고 하면 메카브를 설치해야 하는데 이게 설치가 깔끔하게 잘 안되는 편입니다.
Mecab-ko의 코어 모듈과 Python 모듈까지 설치하는 방법입니다.
간단하게 한 셀로 정리했으니 순서대로 하면 됩니다.
# 아래의 명령으로 설치가 되야 하는데 안되며 포기
# sudo python3.9 -m pip install -v python-mecab-ko
# 메카브의 소스를 받와서 빌드후 설치
wget https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz
tar xzvf mecab-0.996-ko-0.9.2.tar.gz
cd mecab-0.996-ko-0.9.2
./configure
make
sudo make install
# 메카브 한국어 사전을 받아와서 빌드 후 설치
cd
wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz
tar xvfz mecab-ko-dic-2.1.1-20180720.tar.gz
cd mecab-ko-dic-2.1.1-20180720
./configure
sudo apt-get install autoconf
# autogen.sh
# autoreconf
# /etc/ld.so.conf파일에 마지막 한 줄을 추가하고 다시 수행하면 정상적으로 표시가 됩니다.
sudo vim /etc/ld.so.conf
# 아래의 두줄이 들어가면 오케이
# include ld.so.conf.d/*.conf
# /usr/local/lib
sudo ldconfig
make
sudo make install
# 이제 메카브 파이썬 모듀을 설치한다
cd
git clone https://bitbucket.org/eunjeon/mecab-python-0.996.git
cd mecab-python-0.996
python3 setup.py build
python3 setup.py install
# python3 실행해서 다음 코드를 실행해서 에러가 없으면 오케이
# import MeCab
시계열로 고객의 구매패턴을 확인하려면 많은 드릴다운과 데이터 탐색이 필요합니다. 하지만 간단한 특징으로 몇 가지 중요한 인사이트를 얻을 수도 있습니다.
가장 짧은 계졀단위를 먼저 본다
사람의 계절성(Seasonality) 중 가장 짧은 것은 하루입니다. 하루 다위로 어떻게 행동이 반복되는지 보면됩니다.
데이터 탐색에 의한 인사이트
그래프와 자료를 공유할 수는 없지만 위의 데이터는 다음과 같은 간단한 인사이트가 있습니다.
가장 인터넷서핑이 활발한 시간은 10시 ~ 11시, 13시 ~ 18시, 20시 ~ 23시입니다.
구매는 보통 오전 9시경 ~ 10시경, 오후 7시에 새벽 13시까지에 가장 많이 발생한다.
1일 일과의 사용자들의 웹서핑 패턴과 구매 패턴을 분석하면 광고클릭모델이나 광고전환모델을 만들 때 매우 유용한 특성, 자질(feature)에 대한 힌트를 얻을 수도 있습니다.
데이터 설명
우선 위의 그림은 2022년 9월의 추석연휴를 전후로 7일간의 인터넷 사용자들의 여러 웹사이트에서 발생한 웹사이트의 페이지뷰 중의 일부 트래픽의 패턴입니다. PC와 Mobile을 모두 포함한 것인데 모바일과 PC는 양상이 조금 다르긴 합니다.
웹사이트 페이지뷰와 사용자 구매패턴과의 상관관계
여기서 말하는 웹사이트는 뉴스, 신문, 커뮤니티, 각종 블로그를 말하고 인터넷 사용자는 매체를 돌아다니며 콘텐츠를 섭취하는 사람들을 말합니다. 이 사람들은 이런 매체들을 돌아다니가 어느 시점에 광고를 클릭하거나 또는 직접 쇼핑몰에 직접접속해서 물건을 보고 구매를 합니다.
웹사이트 페이지뷰와 사용자들의 구매 패턴과는 상관관계가 있을까? 하는 궁금증이 생길 것입니다.
단순한 아이디어로는 “어느 시간대에 광고를 보여주면 물건을 살까?” 같은 것이 있습니다.
인터넷서핑이 활발한 시간은 직장인들의 출퇴근 시간과 직장내에서의 행동패턴과 관련이 있습니다. 출근 후 앉아서 시간을 때우고 싶어지는 시간대입니다.
구매는 이것과는 다른데 구매는 정신이 또렷하고 바쁘지 않으면서 올바른 판단을 할 수 있는 시간대입니다. 이 시간대에는 구매하려고 봐 두었던 물건의 구매를 확정하거나 가격대 또는 유형이 비슷한 물건을 찾아다니는 특성이 있습니다.
그외에 소소한 인사이트로는
PC사용자에 비해 모바일 사용자는 새벽시간대의 트래픽이 조금 더 많다.
위의 이유로 추정할 수 있는 것은
PC나 데스크탑은 누워서 쓰거나 할 수 없지만 모바일은 편안하게 누워서 새벽까지 사용가능하기 때문입니다. 이 시간대에 사용자들이 소비하는 컨텐츠는 게임, 웹툰, 소설, 틱톡, 유튜브 같은 엔터테인먼트가 많습니다.
fluentd는 데이터 인제스쳔(Data ingestion) 레이어를 구성하는데 매우 유용한 도구입니다.
fluentd를 microk8s로 구성하는 방법입니다.
우분투(Ubuntu)에 microk8s 설치하기
microk8s는 snap으로 설치해야 합니다.
그래서 snap이 없는 우분투 구버전은 먼저 snap부터 설치합니다. 최근 우분투에는 snap이 기본 설치되어 있습니다.
snap설치
sudo apt-get install snapd
microk8s 설치
sudo snap install microk8s –classic
helm3 활성화
계정을 root로 전환합니다. 일반 사용자로 해도 되지만 몇 가지 선행작업이 있어서 조금 귀찮습니다. 여기서는 그냥 root로 하겠습니다.
sudo su – microk8s enable helm3 microk8s helm3 init
init을 하면 이런 에러가 발생할수도 있습니다.
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com Error: error initializing: Looks like “https://kubernetes-charts.storage.googleapis.com” is not a valid chart repository or cannot be reached: Failed to fetch https://kubernetes-charts.storage.googleapis.com/index.yaml : 403 Forbidden
이럴 때는 다음과 같이 해결합니다.
해결법
Use the –stable-repo-url argument to specify the new repository:
helm init –stable-repo-url https://charts.helm.sh/stable –service-account tiller Use the –skip-refresh argument and replace the stable repo:
해결법 실행명령
helm init –client-only –skip-refresh helm repo rm stable helm repo add stable https://charts.helm.sh/stable Upgrade helm to 2.17.0 or later.
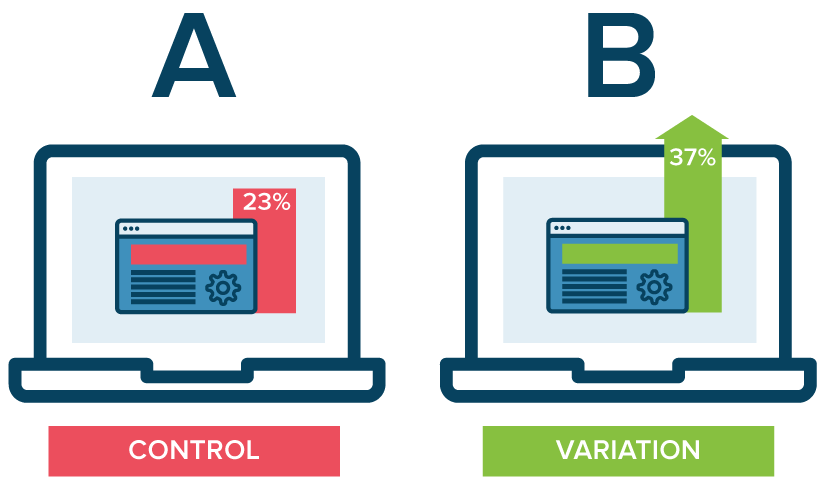
A/B 테스트를 한다고 하지만 정작 테스트 결과를 왜곡해서 해석하거나 자기가 해석하고 싶은대로 해석하는 경우가 많습니다. 오늘은 온라인 서비스에서 하는 A/B테스트에 대한 불편한 사실에 대해서 얘기해 보겠습니다.
A/B테스트의 개념을 제대로 알자
A/B 테스트는 통계학의 실험계획법의 하나입니다. 역사가 오래된 과학적 실험 및 결과 확인 방법입니다. A/B테스트는 의료과학에서 정말 많이하는데 신약, 수술법, 처치법에 대한 테스트를 하기위해서 하고 온라인 서비스에서 UI의 변경이나 기능변경을 할 때 어떤 것이 좋은지 확인할 때도 씁니다.
실험대상을 A군과 B군으로 나누고 B군에 벼환를 주고 그 결과의 차이를 비교한다는 의미해서 A/B 테스트라고 부릅니다.
간단하게 정리하면
아무 처치도 하지 않은 콘트롤 그룹(Control Group, A)과 어떤 처치를 한 테스트 그룹(Threatment Group B)을 두고
Control Group 콘트롤그룹: 아무 처치도 하지 않은 것
Treatment Group 트리트먼트 테스트 그룹: 어떤 특정한 처치를 한 것
이때 Threatment group은 여러개가 있을 수 있습니다. T1, T2, T3이렇게 번호를 붙여서 여러가지 다른 처치를 하게 할 수도 있습니다. 온라인 서비스의 UI라면 UI1, UI2, UI3과 같이 새 UI를 한 번에 테스트해볼 수 있습니다.
콘트롤 그룹과 테스트 그룹의 샘플 수는 같아야 한다
콘트롤 그룹과 트리트먼트 그룹의 샘플 수는 같아야 합니다. 만약 사용자를 대상으로 하는 UI 버킷테스트라면 적용 받는 사용자는 동일하게 분할해야 합니다.
정확히 샘플 수가 같을 필요는 없고 카이스퀘어 테스트를 해서 균둥하다고 나올 정도면 됩니다.
최소한 시즌이 두 번은 반복될 수 있는 기간 동안 진행한다
여기서 말하는시즌은 온라인 서비스의 경우에는 2주를 말합니다. 월별로 특성을 타는 테스트라면 2개월은 돌려야합니다. 시즌을 2번 돌리게 하는 것은 시즌내에서는 특정 시점에 따라 기복이 있을 수 있고 잠시 튀는 경우가 생기기 때문입니다. 그리고 행위나 반응에 대한 샘플 수를 늘리기 위한 것입니다.
여기서 “하루 또는 1시간만하고 테스트 결과가 좋으니 테스트가 더 좋다”라고 판단하는 분들이 많은데 이게 좀 문제입니다. 과학적으로 보면 이건 사기나 마찬가지입니다.
어째서 1시간만 해도 되는지 1일만 해도 되는지 그게 괜찮은지에 대한 근거가 전혀 없습니다. 보통 왜 그 기간동안 하느냐라고 물으면 “그 정도면 충분하지 않을까요?” 라고 말합니다.
매우 비과학적인 사고여서 통계학에서 절대 하지 말아야 할 행위로 규정하고 있는 것입니다. 저렇게 하는 이유는 어떤 테스트 방법으로 어떻게 평가해야 하는지 모르기 때문입니다.
어떤 평가 방법을 써야 하는가?
A/B테스트는 실험을 시작하고 시간이 경과한 후 또는 어떤 처치를 한 후에 두 그룹의 차이가 있는지 없는지, 어떤 것이 더 좋은지를 확인하는 것입니다.
검정법
진행 후에 결과에 대한 검증법은 통계적 검정법을 쓰는데 통계적 검정법은 간단하게는 t-test부터 F-test 등 매우 많습니다. 샘플 수, 상황, 데이터의 분포에 따라 어떤 평가방법을 써야 하는지 각각 다르므로 어떤 평가방법을 써야하는지는 잘 알고 있어야 합니다.
T-test면 다되나?
평균의 유의미한 차이는 T-test를 하면 되고 원래 두 그룹의 평균차이가 달랐다면 부산분석을 통해 분산이 차이가 발생했는지 유의미한지를 확인해야합니다.
CTR이 좋아졌는지 보려면?
예를들어 테스트그룹1이 콘트롤그룹보다 CTR이 좋은지 보려면 2주간 버킷테스를 진행하고 CTR에 대한 T-test를 수행하면됩니다. 이때 CTR의 분포가 정규분포에 가까워야 합니다.
CTR은 하루 또는 전체 기간의 CTR을 계산하는 것이 통상적인데 페이지뷰는 있지만 CTR이 없는 경우에는 CTR이 계산이 안되는 것들은 버리고 불균등한 샘플의 숫자는 많은쪽에서 일부 줄여서 버려야 합니다.
의료과학에서의 A/B테스트
의료과학에서는 실험 대상의 샘플도 적고 콘트롤이 잘 안되고 관찰도 잘 안되는 문제 때문에 매우 어렵습니다. 온라인의 경우에는 콘트롤이 잘되고 샘플도 많습니다만 정작 실험 후에는 판단을 엉망으로 해서 잘못된 판단을 하는 것이 문제지만 의료과학은 케이스가 그때그때 다들 다르다는 문제가 있습니다. 그래서 그때 그때 방법을 선택해서 검정을 해야 합니다. 케이스별로 잘 알려진 통계적 검정법이 있는데 어떤 것을 써야 할지 애매할 때가 많습니다. 이런 경우에는 의료통계 전문가에게 물어봐야 합니다.
의료과학은 결과에 대한 검증이 매우 예민하고 철저하기 때문에 잘 해야하는데 사용해야 합니다. R언어를 사용하는 분들은 논문이 이미 R언어를 사용해서 실험을 평가한 것이 많으므로 관련 논문을 참조하거나 커뮤니티에 물어보면 어떤 테스트를 써야하는지 잘 알려주니 적극 활용할 필요가 있습니다. 미국의 유명한 의료과학 대학과 제약회사들은 모두 R언어를 기본으로 사용합니다.
그래서…
A/B테스트는 버킷을 분리해서 서로 다른 효과를 적용하게 만드는 시스템을 만드는 것이 가장 어렵습니다.
하지만 버킷테스트를 진행하고 나서 실험결과에 대한 올바른 과학적 해석과 그 논리적 결함, 통계적 해석 왜곡에 대한 검증도 매우 중요합니다.
테스트를 진행하고 단편적인 결과만 보거나 자신에게 유리한 것만 본다면 실패한 실험이 되므로 매우 주의해야 합니다.
의료과학에서 얼마나 철저하게 검증하는지 안다면 A/B테스트가 만만하지 않다는 것을 알 수 있습니다. 물론 온라인 서비스의 버킷테스트는 의료과학과는 달리 사람의 생명에 직접적연 영향을 주지 않을
만약 실험 결과에 대한 해석과 검정을 어떻게 하는지 모른다면 아예 하지 않는 것이 오히려 좋습니다.
A/B테스트를 진행하고 나서 그 결과가 믿을 만한 것인지 알고 싶다면 통계학의 가설검정법에 대해 공부해야 합니다.
데이터 기반으로 의사결정을 하는 것은 이미 전세계적으로 당연히 해야 할 것으로 다를 인지하고 있습니다.
하지만 많은 한국회사들은 빅데이터, 데이터과학, 디지털트랜스포메이션을 도입해서 데이터기반 의사결정을 하려고하지만 대부분 실패를 맛보고 예전에 하던 경험기반의 주먹구구식 의사결정을 합니다.
데이터 기반 의사결정이 실패하는 대부분의 이유는 데이터 과학이 사기이거나 데이터 과학자의 역량 부족이나 실패보다는 경영자나 관리자 또는 조직원들의 문제인 경우가 대부분입니다.
즉 실행을 하는 사람들의 인식과 사고와 이해 관계의 문제입니다.
사람의 문제가 대부분입니다.
많은 한국회사들이 지난 십 수년동안 데이터 기반 의사결정을 하기 위한 시도를 했지만 제대로 한 곳은 거의 없습니다. 많은 회사들의 데이터 책임자, 실무자, 의사결정권자들과 얘기하거나 하다보면 처음에는 데이터 기반 의사결정이 꼭 필요하며 꼭 하고 싶다는 말과 함께 시작하지만 대부분 실패하게 됩니다.
여기에는 회사들 마다 나름대로 원인과 이유가 있겠지만 공통적으로 보이는 어이없는 원인들도 있습니다.
우선 조직내에서 수직적 레벨로 어느 위치에 있는지에 따른 문제점들입니다.
결정권자들의 문제 (탑 레벨의 문제)
결정권자들의 경우입니다. 이 경우가 문제가 가장 많습니다. 전후가 어쨌든 의사결정을 하는 최종 결정권자들이기 때문입니다.
보통 조직(회사)내에서는 결정권자들이 데이터기반 의사결정에 대해 무지하거나 잘못된 결정을 하는 것에 대해서 아무도 지적하거나 언급하지 않습니다. 이런 걸 잘못해서 결정권자의 귀에 그런 의견을 말한 사실이 알려지면 속된말로 찍혀서 인사상 불이익을 받거나 하는 문제에 휘말릴 수 있기 때문입니다. 사회생활 잘하고 싶은 것입니다.
필자가 듣거나 경험해 본 결정권자들의 문제는 여러가지 케이스로 나타납니다.
데이터기반 의사걸정을 하는 모양새만 갖추고 싶어한다
원래부터 데이터 기반 의사결정은 할 생각이 없거나 그게 뭔지 본질은 관심이 없는 케이스입니다. 본인이 데이터 기반 의사결정을 하는 합리적이고 선진화된 사람으로 각색되어 보여주길 원하는 것이고 실상 결정을 할 때는 자기가 하고싶은대로 해버립니다.
“데이터로 파악한다고 다 아는 것도 아니고 다 맞는 것도 아니잖아?” 이렇게 생각하거나 말하는 경우도 매우 많습니다.
데이터기반 의사결정 필요성을 아예 모르는 경우도 많습니다. 그냥 남들이 그걸 한다고 하고 그걸 하면 괜찮은 의사결정권자로 보일 것 같으니 그게 포장용으로 필요할 뿐입니다.
“나는 데이터기반 의사결정을 할 줄 아는 선진적이고 진보된 사람이야.” 라는 말을 하며 그런 사람으로 알려지길 바라지만 실제로 행동은 그렇게 하지 않는 것입니다.
수단과 목적이 바뀐 것입니다. 의사결정을 잘하기 위한 것이 목적이고 데이터기반 의사결정은 그걸 하기 위한 방법 중 하나입니다. 그런데 데이터 기반 의사결정을 한다는 것만 보여주고 싶은 것이 목적이고 그 수단으로 그걸 한다는 포장만 하는 것입니다.
안타깝게도 어떤 기업이든지 이런 사람이 거의 필연적으로 그리도 다수 존재합니다.
보고 싶은 것만 본다
데이터 기반의 분석결과는 그 분석이 틀리지 않고 맞다는 전제하라면 좋은 결과가 나올 수도 있고 안좋은 결과가 있을 수도 있고 세부적으로는 좋고 나쁨이 섞여 있을 수 있습니다.
이 중에서 자기가 보고 싶은 것만 봅니다. 그러니까 자기가 하고 싶은 것을지지하는 결과만을 선택하고 그게 아닌 결과는 무시해 버립니다.
이렇게 할꺼면 데이터를 확인할 필요가 없습니다. 그냥 자기가 하고 싶은 대로 하면 됩니다. 하지만 그렇게하면 비론리적이라는 말을 듣기 때문에 논리적이라는 말을 듣기 위한 포장용으로 자신에게 유리한 결가만 필요한 것입니다.
어떤 실험, 사실 탐색, 인사이트 도출과 같은 것은 보통 좋은 사실과 나쁜 사실이 뒤섞여 나오는경우가 많습니다. 대표적인 실수는 여기에서 자신이 원하는 결과에 유리한 것만 채택하고 나머지는 별거 아니라고 무시해 버리는 것은 가장 경계해야 할 것이고 그렇게 하지 않는 것은 도덕적으로 문제가 있는 것입니다.
데이터를 보긴 하지만 결정 자체를 안한다
의사결정이란 시의적절하게 해야 합니다. 즉 할 때는 해야 하는데 무조건 의사결정을 안합니다. 데이터를 보는 이유는 사람의 경험에 의한 의사결정이 왜곡이 많거나 틀릴 위험이 많기 때문에 최대한 현실을 제대로 보고 참고해서 결정을 하기 위한 것입니다.
결정을 안 하는 결정권자는 데이터 기반이든 아니든 문제가 매우 많습니다.
이런 결정권자가 있는 회사는 서서히 망합니다.
다행인 것은 당장 망하지는 않습니다. 하지만 더 불행인 것은 이런 회사는 반드시 망합니다.
매니지먼트 레벨들의 문제
본부장, 센터장, 사업장, 유닛장, 팀장 등과 같은 상위 또는 중간 매니저들의 문제입니다.
이런 사람들도 데이터기반 의사결정에 문제를 만드는 경우가 많습니다. 사실 문제를 가장 많이 만드는 사람들은 이 사람들입니다.
위에서 하라고 시키니까 하는 척만 한다
위에서 “데이터 기반으로 의사결정” 하자고 탑다운으로 지시가 내려온 경우입니다. 그게 뭔지도 모르겠고 인터넷 검색을 하고 업체를 찾아서 하는 시늉을 합니다.
그러고나서 “이거 잘 안되는거네. 거봐 사기라니깐” 이렇게 말합니다.
원래부터 하고 싶은 생각이 없었던 것입니다.
뭔지, 왜 해야하는지 학습할 생각은 없습니다. 뭔지 다 이해했지만 본인이 충분히 잘하기 때문에 그런 it인력이나 솔루션 업체들 돈이나 퍼주는 그런 것은 낭비라고 생각하는 것입니다.
부하직원에게 말해도 무슨 말인지 알아듣지 못한다
데이터 기반을 왜 해야하는지 같이 일을 해야 할 팀 동룝 또는 부하직원들이 이해를 못하는 경우입니다. 혼자 데이터 추출하고 데이터 검증을 하거나 데이터 관련 부서로부터 협조를 받아야 하지만 그렇게 하지 못하는 경우도 많습니다.
데이터 기반 의사결정에 필요한 기술이 없다
태블로 같은 BI도구를 사거나 하둡, 스파크, 빅쿼리, GCP같은 것을 써서 카운트를 세고 그래프를 예쁘게 그리고 나서 의사결정을 하면 데이터기반 의사결정이라고 생각해버립니다.
데이터를 집계하고 시각화하는 것이 데이터 기반 의사결정을 하기 위한 출발점이긴하지만 데이터 기반 의사결정은 그런 그래프와 데이터를 보고 여러가지 고민과 생각과 탐색을 해서 결론을 내는 것입니다. 즉 데이터를 제대로 집계하거나 추출, 가공하고 시각화한 데이터 요약을 해석 하는 방법을 터득해야 합니다. 그런데 그 방법은 익히기 매우 어려운 기술이고 잘 정리된 튜토리얼이 없습니다.
그래서 본인이 잘하고 있다고 착각하기 쉽지만 실상은 아닌 경우가 많습니다.
실무자들의 문제
마지막으로 실무자들의 문제가 있습니다. 즉 데이터 과학자, 데이터 분석가가 아닌 사람들입니다.
대부분의 실무자들은 데이터기반의 어쩌고 하는 것에 대해 기본적인 거부감을 가지고 있습니다.
뭔지 잘 모를말로 자신들보다 지적, 과학적으로 우위에 있다는 것을 과대포장하기 위해 데이터기반이라는 것을 만들어냈다고 생각하는 것입니다.
“실제로 해보니 안되드라”
데이터분석을 하고 인사이트 도출을 위한 미팅을 하기 위해서 초기 셋업 미팅을 하면 이런 피드백을 꽤 많이 합니다.
그리고 이런 상황에서 시작하는 프로젝트는 실상을 보면 애초에 협조하거나 잘되길 바라지 않고 방해하는 일이 허다합니다.
데이터기반으로 의사결정을 하게 되면 경험기반의 자신들의 노하우가 쓸모가 없어지는 것 같고 컴퓨터에게 자신들의 일자리를 잃어버릴 것 같은 느낌 때문입니다.
즉 애초레 제대로 할 생각도 없었고 잘 안되길 바라고 그렇게 되도록 행동한 것입니다.
“내가 진짜로 여러 번 같이 해봤는데 그거 현실성이 없더라니깐”
이렇게 말하는 사람들도 다수입니다.
앞서 말했듯이 제대로 안해봤거나 사실은 여러번 안해본 것입니다.
반약 데이터기반 의사결정이라는 것이 말만 그럴듯하고 정말로 안되는 거라면 데이터기반 의사결정은 꼭 필요한 것이며 많은 실수를 바로잡았다고 말해온 실리콘벨리의 선진적인 회사들은 모두 단체로 거짓말과 사기를 치고 있는 것입니다.