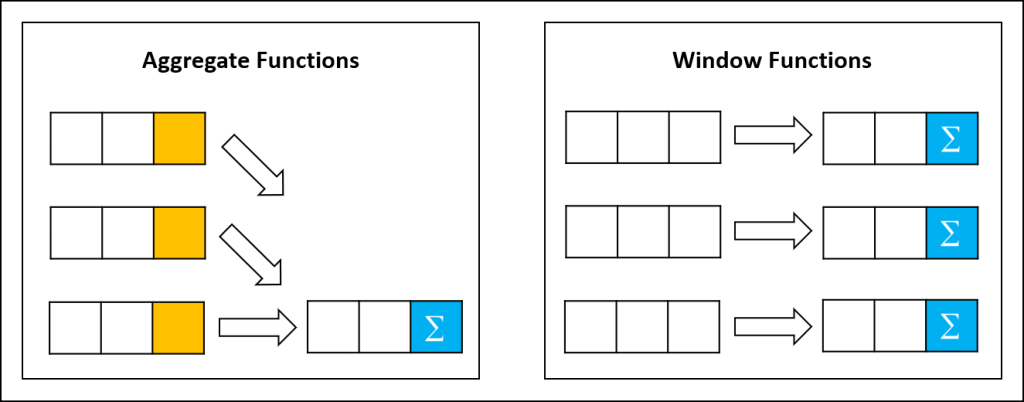
시퀀스 데이터 프로세싱은 다음과 같은 문제가 있습니다.
- window function은 where와 같은 조건을 지정해서 프레임내에 로우를 선택할 수 없습니다. 지원하는 경우도 있지만 드뭅니다.
- 시퀀스 데이터프로세싱은 매우 중요하지만 분산처리를 하기 매우 어렵기 때문에 처리 속도가 느리거나 정합성을 일부 포기해야 하는 문제가 있습니다.
- 시퀀스 데이터프로세싱은 미래에 결정된 데이터에 따라 과거의 데이터를 업데이트하는 것이 매우 어렵거나 되지 않습니다. (Google DataFlow와 같은 것은 가능)
기억해야 할 것
- 윈도 펑션의 안과 바깥의 구분
- “윈도 펑션의 결과값은 결국 1개의 값”
- 특정 그룹의 시퀀스 토큰별로 그룹만들기
- 값의 변화에 대한 기록 방법
- 특정 프레임의 조건을 만드는 트릭
- 태깅값에 의한 집계
예제 준비중