“팔 여러 개 달린 산적” “Multi Armed Bandit”은 슬롯머신의 별명인데 이 알고리즘은 이름처럼 “어떤 슬롯 머신의 팔을 당겨야 돈을 딸 수 있는가?” 와 같은 문제를 풀기위한 방법입니다.
엄밀한 의미의 강화학습에 포함되지 않지만 상당히 간단하고 쓸만하고 강화학습의 개념을 익히기 좋기 때문에 강화학습을 설명할 때 가장 먼저 설명하는 것이기도 합니다.
여러 대의 슬롯 머신이 있고 이 슬롯 머신 중 어떤 것의 레버를 당겨야 돈을 딸 수 있는가를 푸는 문제입니다. 한 번에 1대의 슬롯머신의 레버를 당기고 계속해서 반복합니다.
이 문제의 전제 조건이 있는데 한 번에 하나의 슬롯머신의 팔을 당길 수 있다는 것입니다.
그래서 동시에 모든 슬롯머신의 팔을 당겨서 그리고 여러번 당겨서 어떤 슬롯머신이 돈을 딸 학률이 높은지 알아낼 수 없습니다.
그래서 한 번에 하나씩만 선택해서 돈을 최대한 많이 따는 것이 이 문제의 푸는 목적입니다.
복잡한 공식은 여기에 안 적겠습니다. 구글에서 찾아보시면 수식과 코드가 다 있습니다.
첫번째 방법. Greedy 욕심쟁이
모든 슬롯머신에 순차적으로 한 번씩 팔을 내려봅니다. 그래서 돈을 못땄다면 다시 한 번씩 다 팔을 내려봅니다.
몇번을 수행한 후에 딴 돈이 가장 많은 슬롯머신에게 계속해서 몰빵합니다.
이게 그리디(Greedy, 탐욕스러운) 방식입니다. 단순하면서도 조금 무식한 방법입니다.
두번째 방법. epsilon
Greedy 방법을 사용하되 무작정 사용하지 않고 랜덤으로 팔을 당길 확률을 정해놓습니다.
만약 50%의 확률로 랜덤을 고르겠다고 하면 한 번은 지금까지 가장 돈을 많이 딴 슬롯머신을 당기고 한 번은 랜덤으로 아무것이나 고르는 방법입니다.
그나마 다른 것들에게 기회를 준다는 것 때문에 낫습니다.
epsilon이라는 이름은 랜덤으로 고를 확률값을 epsilon이라고 이름을 붙여서 부르기 때문입니다.
세번째 방법. UCB(Upper-Confidence-Bound)
위의 epsilon에서 약간의 공식을 주어서 랜덤 찬스가 왔을 때 무조건 랜덤으로 어떤 슬롯머신을 팔을 다기지 않고 덜 뽑혔던 슬롯머신에 가중치를 두어서 더 뽑아서 팔을 내려줍니다.
네번째 방법. Tompson sampling
톰슨 샘플링은 설명을 하면 조금 복잡해지는데 확률 분포 중 하나인 베타분포를 이용해서 확률이 가장 높은 것을 선택하는 것입니다.
베타분포 함수에 선택된 횟수와 돈을 딴 횟수를 입력하면 베타분포를 각각 구할 수 있고 그 베타분포를 확률 분포로 이용해서 값을 구하면 선택할 것을 찾을 수 있습니다.
저장된 데이터를 이용할 수 있는 장점이 있고 UCB 보다 성능이 조금 더 좋아서 온라인 추천 시스템에서 많이 이용되고 있습니다.
A/B 테스트와 MAB의 관계
A/B 테스트는 통계학의 실험계획법 중 하나 인데 2개 또는 2개 이상의 그룹을 동일한 수(최대한 비슷한 수) 만큼 각각 분할해서 한쪽에만 다른 처리를 해서 두 그룹의 차이를 보는 방법입니다
온라인에서는 흔히 버킷테스트라고 하는 방법입니다.
예를 들어 광고배너가 있는데 원래 배너는 테두리가 하얀색인데 테두리를 빨간색으로 바꿨을 때 사람들이 어떤 것을 클릭을 더 많이 하는지 알아 보고 싶을 때 같은 경우에 합니다.
A/B 테스트가 오랫동안 사용한 방법이기 때문에 잘 알려져 있지만 문제는 두 그룹을 방해받지 않게 불한하는 방법이 상당히 어렵고 두 그룹의 차이를 알아보는 방법이 데이터의 양상과 원래 데이터의 특성에 따라 여러가지 통계적인 방법을 써야하는 데 실수로 잘못된 방법으로 확인을 했다고 하더라도 그 실수를 알아내기 어렵다는 문제가 있습니다.
A/B 테스트를 하는 것은 많이 어렵지 않지만 A/B테스트의 결과를 해석하는 것은 매우 숙련된 통계학자가 필요하고 시간도 많이 걸립니다.
그래서 A/B 테스트를 하지 않고 각각 반응을 그대로 볼 수 있는 어떤 환경이 있다면 그 환경에서는 각각 매번의 결과에 따라서 결과가 좋은 것에 점수를 더 줘서 그것을 선택하게 만드는 방법을 쓰자는 것입니다.
그래서 MAB는 온라인 시스템의 추천시스템이나 평가에 굉장히 적합합니다.
광고시스템과 MAB
한 번에 5개의 제품을 동시에 보여지는 광고 이미지가 있다고 가정합니다.
사용자 별, 또는 사용자 그룹별로 어떤 제품에 더 관심을 가지는 지를 보고 클릭을 많이 하는 제품을 MAB에 의해서 더 많이 노출한다고 하겠습니다.
흔히 쓰는 방법이지만 이게 문제가 좀 있습니다.
선택할 제품이 매우 많은 경우에는 못합니다. 아마도 제품의 카테고리가 있고 그것들 중에 가장 잘 팔리는가 하는 전략을 취할 수 있지만 상식적으로 좋은 방법은 아닐 것입니다.
선호도는 계절성 효과, 요일 효과, 캠페인에 피로도에 따라 달라집니다. 슬롯머신 처럼 확률이 안변한다는 가정을 두기가 좀 어렵습니다. 변동이 너무 많습니다.
또 가중치를 변경하는 것 때문에 생기는 문제가 파생적으로 생기는데
쿠키로 인해 신규 및 재이용자의 분포에 영향을 미칩니다.
변화에 대한 적응이 느리기 때문에 인해 관성때문에 결과가 왜곡될 수 있습니다.
아주 단순한 경우에만 사용이 가능하며 복잡한 시스템으은 오히려 결과를 왜곡할 수 있습니다.
저렇게 선택한 것이 여전히 가장 좋은 방법 또는 그리 좋은 선택이 아닐 수도 있겠지만 그 자체를 확실하게 확인 못합니다. 이건 다른 알고리즘도 동일한 문제이긴 합니다만.
이런 것은 KNN (K-nearest-neighbor) 와 같은 기계학습 모델에 사용하는 것입니다. KNN은 판별 모델에서 사용할때 매우 강력한 알고리즘이지만 검색할 때 너무 느리고 자원을 많이 사용하는 문제로 인해서 실제로는 거의 사용을 못하는 알고리즘이지만 Faiss를 이용하면 이걸 쓸 수 있습니다.
Faiss 색인을 생성할 때 벡터의 차원을 지정해주고, Index의 유형도 결정을 해줘야 하는 것이 중요합니다. 검색은 입력한 k의 갯수만큼 리턴하게 되어 있고 벡터의 색인 번호와 거리를 리턴하게 되어 있늡니다.
색인 번호는 그냥 입력한 입력한 벡터의 순번입니다.
import faiss
import numpy as np
import random
# Euclidean distance 기반으로 가장 가까운 벡터를 찾는다.
# 랜덤으로 10차원 벡터를 10개 생성
vectors = [[random.uniform(0, 1) for _ in range(10)] for _ in range(10)]
# 10차원짜리 벡터를 검색하기 위한 Faiss index 생성
index = faiss.IndexFlatL2(10)
# Vector를 numpy array로 바꾸기
vectors = np.array(vectors).astype(np.float32)
# 아까 만든 10x10 벡터를 Faiss index에 넣기
index.add(vectors)
# query vector를 하나 만들기
query_vector = np.array([[random.uniform(0, 1) for x in range(10)]]).astype(np.float32)
print("query vector: {}".format(query_vector))
# 가장 가까운 것 10개 찾기
distances, indices = index.search(query_vector, 10)
# 결과룰 출력하자
idx = 0
for i in indices:
print("v{}: {}, distance={}".format(idx+1, vectors[i], distances[idx]))
idx += 1
Faiss로 코사인 유사도로 검색하기
유클리디안 거리(Euclidean Distance)로 가장 가까운 벡터를 찾으면 특정 차원의 양적 수치에 따라는 거리가 가깝다고 판별되는 편향의 문제가 있습니다. 이게 문제가 될 때가 있고 그렇지 않을 때가 있는데 이것은 문제의 도메인에 따라 다릅니다. 그러니까 문제가 주어진 환경에 따라 그때그때 다르다는 뜻입니다.
이런 문제를 피하는 방법은 유사도를 계산할 때 거리측정 방법을 유클리디안 거리를 사용하지 않고 코사인 유사도를 사용해서 벡터의 방향이 가까운 것을 찾는 것입니다. 보통 검색엔진들도 이 방법을 기본으로 사용합니다.
Faiss도 이걸 지원하는데 예제는 아래 코드를 보시면 되고 앞서 설명했던 유클리디안 거리 기반의 검색과 다른 점은 index를 생성할 때 타입을 다르게 생성해야 하고 벡터를 노말라이즈 해줘야 한다는 것입니다. 벡터가 이미 노말라이즈되어 있다면 안해도 됩니다.
import faiss
import numpy as np
import random
# 코사인 유사도 (Cosine Similarity) 를 이용해서 가장 가까운 벡터를 찾으려면 몇가지를 바꿔줘야 한다.
# 코사인 유사도 (Cosine Similarity) 를 사용하려면 벡터 내적으로 색인하는 index를 만들면 된다.
# 코사인 유사도를 계산하라면 벡터 내적을 필연적으로 계산해야 하기 때문이다.
# 랜덤으로 10차원 벡터를 10개 생성
vectors = [[random.uniform(0, 1) for _ in range(10)] for _ in range(100)]
# 10차원짜리 벡터를 검색하기 위한 Faiss index를 생성
# 생성할 때 Inner Product을 검색할 수 있는 index를 생성한다.
index = faiss.IndexFlatIP(10)
# 아래는 위와 동일하다.
# index = faiss.index_factory(300, "Flat", faiss.METRIC_INNER_PRODUCT)
# Vector를 numpy array로 바꾸기
vectors = np.array(vectors).astype(np.float32)
# vectors를 노말라이즈 해준다.
faiss.normalize_L2(vectors)
# 아까 만든 10x10 벡터를 Faiss index에 넣기
index.add(vectors)
# query vector를 하나 만들기
query_vector = np.array([[random.uniform(0, 1) for x in range(10)]]).astype(np.float32)
print("query vector: {}".format(query_vector))
# 가장 가까운 것 10개 찾기
distances, indices = index.search(query_vector, 50)
# 결과룰 출력하자.
idx = 0
for i in indices:
print("v{}: {}, distance={}".format(idx+1, vectors[i], distances[idx]))
idx += 1
제 계획대로라면 벌써 몇년전에 포스팅을 했어야 했지만 계획대로 되는 것은 언제나 그렇듯이 없습니다.
CART는 GBDT, Random Forest, XGboost, LightGBM 등의 트리계열 알고리즘의 근간이 되는 매우 중요한 알고리즘입니다. 요즘 트리 계열 알고리즘에서 가장 좋은 성능을 보이는 XGboost에게는 할아버지쯤 되는 알고리즘입니다.
CART에는 결정 트리(Decision Tree)와 회귀 트리(Regression Tree)라는 알고리즘이 2개 들어 있습니다. 한 개가 아닙니다. 그런데 둘은 거의 비슷하기 때문에 1개라고 봐도 무리가 없긴 합니다. 일란성 쌍둥이라고 생각하면 됩니다. CART는 Classification And Regression Trees의 약어인데 여기에도 분류와 회귀를 하는 트리라는 것을 알려주고 있습니다.
어쨌든 이 둘의 차이는 뒤에 설명하겠습니다.
알고리즘의 컨셉
알고리즘의 컨셉은 간단합니다. 학습 데이터를 해석해서 알아서 트리 구조를 자동으로 만든 다음 만들어진 트리를 이용해서 분류, 예측 문제를 해결하는 모델을 만드는 것입니다.
여기서 중요한 것은 트리를 자동으로 만든다는 것입니다. 트리를 사람이 만들어줘야 한다고 상상하시는 분들이 있는데 아닙니다.
분류 트리와 회귀 트리의 차이
분류 트리와 회귀 트리의 차이를 살펴보겠습니다.
결정 트리(Classification Tree)는 클래스(등급) 또는 레이블(표 딱지)을 예측하는 것으로 “남”또는 “여”, “예” 또는 “아니오”, “A”, “B”, “C” 와 같이 어떤 것인 맞추는 것(판별)이고
회귀 트리(Regression Tree)는 연속형 숫자인 1,2,3 123, 28.5와 같은 숫자를 맞추는 것입니다. 사람의 키를 맞춘다거나, 대출 상환 예상액을 맞춘다거나 하는 것(예측)입니다.
CART의 탄생
뭐든 그렇지만 자세한 설명 전에 역사를 조금 살펴보면 이해하는데 도움이 됩니다.
CART는 1980년대에 발표된 것으로 이제 나이가 들대로 든 알고리즘이지만 아직도 현역에서 많이 쓰입니다. 기계학습 알고리즘이 다들 독특한 면이 있긴하지만 CART도 상당히 독특한 기계학습 알고리즘입니다. 이 알고리즘은 학술상의 갈래로 보면 데이터마이닝 계열로 많이 분류됩니다. 비즈니스적인 결정을 과학적으로 해서 가치 창출얼 하기 위한 것. 그러니까 좋은 결정을 내리는 것을 자동화하기 위한 용도로 만들어진 것입니다.
만든 분들의 말에 의하면 통계 분석이나 문제 해결을 할 때 마다 회귀모델같은 통계 모델이나 여러 수리 모델을 매번 디자인하고 적용하는 것이 비효율적이라서 싫었다고 합니다.
데이터마이닝 계열이라고 했지만 이것도 기계학습 알고리즘이고 만들어진 원리를 보면 꽤 깊은 고급 통계 이론과 정보 이론이 함축되어 있습니다. 만만한 알고리즘은 아닙니다. 이 알고리즘의 저자들이 총 4명인데 통계학, 과학, 의학, 경제학, 컴퓨터 공학에 매우 뛰어난 석학들입니다. 이 알고리즘이 이런 분야에 고루 쓸 수 있는 다목적 도구라고 해석해 볼 수 있습니다.
CART의 저자와 논문
보통 알고리즘은 논문으로 많이 발표되는데 CART 알고리즘은 논문이 없습니다. 논문으로 발표된 알고리즘이 아니고 책으로 발표된 알고리즘입니다. 논문을 찾다가 논문이 없고 대신 책이라는 사실에 충격받았던 기억이 있습니다.
오래된 책인 만큼 표지가 매우 촌스럽습니만 아마존에서 아직도 판매하고 있습니다. 출판일을 보면 1984년 1월 출판이 첫판입니다.
CART의 저자들
앞서 말씀드렸듯이 책 표지에 있는 저자 4명은 모두 각 분야에서 상당히 유명한 분들입니다. 아래의 4명입니다.
Leo Breiman – University of California, Berkeley
Jerome H. Friedman – Stanford University
Richard A. Olshen – Stanford University
Charles J. Stone – University of California, Berkeley
책의 저자들까지 나열한 것은 위의 저자들 중에 Leo Breiman (레오 브라이먼) Jerome H. Friedman (제롬 프리드먼) 이름을 굳이 외우실 필요는 없습니다만 이 두 사람은 알아두는 것이 기계학습을 깊이 공부하신다면 도움이 되기 때문입니다. 이 두 사람은 CART 발표 이후에 Random Forest(랜덤 포레스트)와 GBDT (Gradient Boosted Decision Tree), GBRT(Gradient Boosted Regression)를 만든 사람들입니다. 아마 기계학습을 조금이라도 공부하신 분들은 이 알고리즘들의 이름을 알고 있을 것입니다. 특히 랜덤포레스트는 너무도 유명하지요. 그리고 부럽게도 위키피디아에도 이 분들 이름이 등록되어 있습니다.
CART와 유사한 알고리즘
ID3, C4.5, C5.0 이라는 결정 트리(Decision Tree)알고리즘이 있습니다. 나열한 순서대로 개량된 버전인데 C4.5가 가장 많이 알려져 있습니다. CART와 유사하다고 하는데 동일한 시대에 발표된 것이지만 관련은 없다고합니다. 구조도 서로 비슷하다고 알려져 있습니다만 제가 이 알고리즘은 잘 알지 못합니다.
CART가 현재는 라이센스가 없이 무료인 반면 C4.5 구현체가 판매되었던 알고리즘이라서 사용자가 많지는 않습니다. 성능은 꽤 좋다고 하며 CART와 C4.5의 성능은 비슷하다고 알려져 있습니다.
CART의 개량형, 강화형
CART의 개량형, 강화형 또는 영향을 받은 것은 다음과 같은 것들이 있습니다.
Random Forest
Gradient Boosted Decision Tree / Gradient Boosted Regression Tree
XGboost
lightGBM
CatBoost
Isolation Cut Forest
Robust Random Cut Forest
앞서 말했듯이 요즘 각광받는 XGboost, lightGBM도 모두 CART 계열입니다. 현재 결정 트리 계열 중에 가장 주목받는 것은 lightGBM 입니다. 그래서 요즘은 CART를 사용하지 않고 바로 lightGBM이나 XGboost를 사용하는 경우도 많습니다. 다만 CART만 앙상블 모델이 아니고 다른 알고리즘은 모두 앙상블 모델입니다. 앙상블 모델은 여러 모델을 합쳐서 하나의 모델로 만든 것을 말합니다.
위의 알고리즘 중에서 저는 개인적으로 lightGBM을 매우 좋아합니다만 그 이유는 XGboost이 비해서 가볍고 범주형 변수를 지원하기 때문입니다. 자세한 얘기는 다음 기회에 하기로 하겠습니다.
Decision Tree와 Regression Tree의 차이
Decision Tree(결정 트리, 분류 트리)와 Regression Tree(회귀 트리)는 매우 유사합니다. Decision Tree가 남,녀와 같이 클래스 또는 레이블로 된 것을 분류해주는 Classification(분류) 문제 해결이라면 Regression Tree는 몸무게, 키, 확률 등의 연속형 수치값을 추정해주는 Regression 입니다.
참고로 Regression Tree에는 흔히 말하는 Linear Regression과 같은 회귀 모델이 들어 있지 않습니다. 연속형 값을 추정하는 것을 넓은 의미로 Regression(회귀)라고 하는데 Regression Tree는 종단 노드에서 평균을 사용해서 결과값을 추정합니다. 평균을 사용해서 추정하는 것은 넓은 의미에서 회귀라고 말 할 수 있습니다.
설명이 어려워졌는데 쉽게 말하자면 Regression Tree에서 말하는 Regression은 Linear Regression(선형회귀)나 Logistic Regression(로지스틱 리그레션)에서 말하는 그 회귀(Regression)이 아닙니다.
CART의 원리
복잡한 수식 같은 것을 적으려면 시간과 지면이 많이 필요합니다. 우선 원리만 적고 자세한 것은 나중에 업데이트하도록 하겠습니다.
CART 위와 같은 트리를 자동으로 만드는 것입니다. 위의 그림은 CART에서도 Decision Tree를 설명한 것인데 남 (Male), 여 (Female)를 구분하는 판별 모형을 만들때 입력 변수(Input variable, feature, 자질)인 키 (Height)와 몸무게 (Weight)를 이용하는 Decision Tree입니다.
입력 변수는 범주형 변수를 넣을 수도 있습니다. 만약 머리색을 입력 변수 중 하나로 추가해서 넣는다고 하면 Black, Brown, Pink 등과 같은 것이 됩니다. 출력 클래스도 남, 여가 아닌 남,여,모름 이렇게 3개 이상을 지정할 수 있습니다. 단 Decision Tree에 해당하고 Regression Tree는 안됩니다.
이 차이를 모르면 소숫점이 있는 수치 계산을 하다가 반올림 처리 방식의 차이로 인해 오차가 생겼다고 생각하고 정합성을 맞추려다 헤메는 경우가 있을 수도 있습니다.
물론 평생 이런 일이 없을 수도 있습니다.
제가 학생이던 시절에 금전 계산을 자동으로 복잡하게 하는 정산 소프트웨어를 의뢰받아 만든 적이 있었는데, 의뢰인이 제시해준 계산 방법과 확인용 정산 출력물을 기반으로 계산 소프트웨어를 작성하는 흐름으로 진행했었습니다. 단위 계산이 조금 복잡했고 반복 계산을 한 뒤에 복잡하게 역산하는 것을 한 뒤에 총 결과를 산출하는 것이었습니다. 요즘 용어로 바꾸자면 최적화 비슷한 것이었습니다.
그런데 문제가 생겼습니다. 만들 때 적은 양의 데이터로 단위 계산을 몇 개 실험해서 해본 뒤에 나온 결과를 보고 정확하게 계산되었는지를 정확하게 확인했고 문제가 없었습니다, 그 후에 전체 계산을 수행하는 것을 진행해서 총합을 확인해보니 정답지와 결과값이 미세하게 달랐습니다. 다시 단위 계산을 몇개 임의로 선택해서 결과가 어떻게 다른지 점검해 봤는데 몇개가 다르게 나온다는 것을 알았습니다. 이 문제의 원인을 찾느라 시간을 쓸데없이 허비한 적이 있습니다.
물론 이 차이로 인해 큰 일이 생기는 것은 아니었습니만 숫자는 틀려도 문제의 원인을 알지 못하면 곤란하다는 의뢰인의 말에 원인을 찾아야 했습니다.
찾아 본 결과 원인은 제가 사용하던 컴퓨터 랭귀지에서 제공하는 round 함수가 사사오입이 아닌 뱅커스 라운딩을 채택했기 때문에 발생한 문제였고 round 함수를 사사오입 방식의 다른 round로 변경해서 해결했었습니다. 그 뒤로는 round를 하게될 일이 있으면 반드시 사용하는 소프트웨어의 round가 사사오입 방식인지 뱅커스 라운딩인지 확인을 하고 작업을 시작하는 습관이 있습니다. 그게 아니면 오차가 좀 크더라도 정합성을 위해서 무조건 소숫점이하는 절사 시켜버리곤 했습니다. 물론 요즘은 이것마저도 잘 하지 않는 늙은이가 되었습니다만.
어쨌든 그 당시에는 컴퓨터 랭귀지의 기본 함수에 버그가 있는 줄 알고 컴파일러 판매회사에 문의하려고 했었으나 함수 매뉴얼을 먼저 찾아보니 천절하게 설명을 해 두었더군요. 함수 매뉴얼을 자세히 읽지 않은 제가 문제였던 것이고 그리고 관련 자료를 더 찾아보고는 제가 반올림에 대해서 상당히 무식했다는 사실을 알았습니다.
“세상에 반올림 방법은 딱 하나 인 줄 만 알았어” 라고 생각했습니다. 배운 것이 그것뿐이라서요.
앞서 말씀드린 것 처럼 반올림은 여러가지 방식이 있습니다. 꽤 많은 방식들이 있습니다만 우리가 흔히 접할 수 있는 것은 위에서 말한 2가지인 사사오입과 뱅커스 라운딩입니다. 이 포스트에서 사사오입과 뱅커스라운딩의 차이를 설명하겠습니다.
사사오입( 四捨五入 ) 반올림
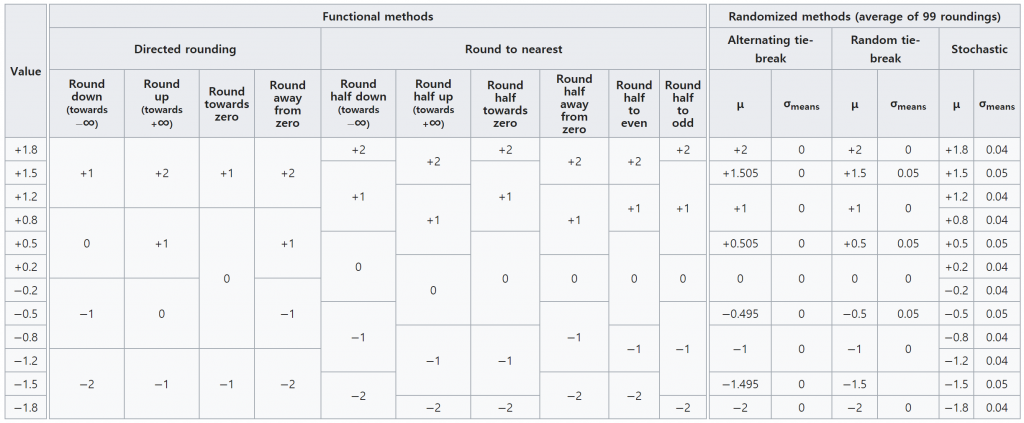
우선, 흔히 아는 반올림은 사사오입인데 4는 버림, 5는 올림을 뜻합니다. 보통은 우리는 그냥 “반올림”이라고 하지만 명확환 구분과 설명을 위해서 “사사오입”이라고 하겠습니다. 사사오입 방식은 영어로는 Round, away from zero (0으로부터 멀어지는 이라는 뜻) 라고 합니다. 사사오입으로 소숫점이 있는 숫자들을 정수로 반올림한다고 하면 다음과 같은 결과가 나옵니다.
0.4 반올림 하면 0 0.5 반올림 하면 1 0.6 반올림 하면 1 1.4 반올림 하면 1 1.5 반올림 하면 2 1.6 반올림 하면 2 2.4 반올림 하면 2 2.5 반올림 하면 3 2.6 반올림 하면 3
잘 알고 있는 그 방식입니다.
뱅커스 라운딩 (오사오입 반올림)
뱅커스 라운딩은 올려질 값이 5인 경우에 만들어질 수의 끝이 짝수가 되도록(짝수에 수렴) 하는 방식입니다.
짧게 “짝수로 맞춘다”로 기억하면 편합니다.
오사오십의 영어 표현은 Round, half to even (절반을 짝수쪽으로)라고 합니다. 금융권에서 많이 채택해서 쓰기 때문에 뱅커스 라운딩이라는 별칭으로 많이 불립니다. 이건 미국의 경우이고 한국 금융권에서도 이것을 채택해서 쓰는지는 모르겠습니다.
어쨌든 뱅커스라운딩으로 계산하면 다음과 같이 됩니다. 굵은 글씨 부분을 자세히 보세요.
0.4 반올림 하면 0 0.5 반올림 하면 0 <– 여기 0.6 반올림 하면 1 1.4 반올림 하면 1 1.5 반올림 하면 2 1.6 반올림 하면 2 2.4 반올림 하면 2 2.5 반올림 하면 2 <– 여기 2.6 반올림 하면 3 2.45 반올림 하면 2 <– 여기
숫자 몇개를 반올림해서 사사오입과 뱅커스라운딩 둘을 비교해보면 이렇습니다.
대상값 / 방식
사사오입
뱅커스 라운딩
0.4
0
0
0.5
1
0
1.4
1
1
1.5
2
2
1.6
2
2
2.4
2
2
2.5
3
2
2.6
3
3
4.5
5
4
4.4445
5
4
사사오입가 뱅커스라운딩의 비교표
뱅커스 라운딩은 미국 측정 계산의 표준이라고 알려져 있습니다. 직접 물어봐서 확인해 보지 않았지만 온라인 문서에 그렇게 적혀 있습니다. 그래서 최신의 컴퓨터 언어나 계산 관련 소프트웨어들에서 기본으로 지원하는 반올림 함수는 우리가 아는 사사오입 방식이 아닌 뱅커스 라운딩을 사용하는 것이 많습니다.
소프트웨어들이 여전히 미국산이 많기 때문인데 특히 과학계산 용도로 쓰는 것들이 그렇습니다.
반올림? 이라는 용어
사사오입은 엄밀히 말하면 반올림이 아닙니다. 우리가 쓰는 반올림은 영어로 round라고 하는데 round라고 하는 것의 원래 뜻은 숫자를 단순하게 만드는 것을 말합니다.
round 는 둥글게 심플하게 밋밋하게 한다는 뜻입니다.
그래서 “무조건 올림”은 영어로 round-up이라고 하고 “무조건 내림”은 영어로 round-down이라고 합니다. round라는 단어가 들어 있지만 “무조건 내림”과 “무조건 올림”은 반올림이 아닙니다. 반만 올리는 것이 아니라 그냥 올리고 내리는 것이지요.
그러니까 영어로 round라고 하는 것을 우리식으로 반올림이라고 표현하는 것은 맞지 않다라고 말씀하시는 분이 있는데 저도 그게 맞다고 생각합니다.
그리고 사사오입 반올림의 영문 표현이 away from zero인데 뜻을 보면 5를 0에서 멀어지게 하는 것이라서 반올림이라고 표현하는 것에 무리가 있다고 합니다. 반면 half to even 방식은 짝수방향으로 반을 올려주거나 절사하기 때문에 이것이 진짜 반올림 방식 중 하나입니다.
하지만 이미 관행으로 다들 사사오입을 반올림이라고 말하기 때문에 편의상 여기에서도 모두 합쳐서 다 “반올림”이라고 하겠습니다.
뱅커스 라운딩을 사용하는 이유
계산과정에서 반올림 때문에 발생하는 오차를 줄이기 위해서 고안된 것입니다. 반복계산을 하면서 반올림이 계속 반복되면 결국 오차를 만들게 되는데 반복 계산 후 최종 결과에서 이 반올림들에 의해 발생하는 오차를 줄이도록 하려는 것입니다.
지인 분이 알려주셨는데 해석학에서 이걸 증명하는 것이 나온답니다.
하지만 간단하게 설명하면 숫자 0과 1이 있습니다. 이 사이에 존재하는 소숫점 첫째자리까지의 수만 보면 다음과 같이 9개의 숫자가 있습니다. 10개가 아닙니다.
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
이 숫자들을 다 반올림한다고 할 때 0.5는 정확하게 한가운데 있기 때문에 절사해서 버릴 것인지 1로 올려줄 것인지가 고민이 됩니다. 그리고 어느쪽으로 하든 오차를 만듭니다.
사사오입 방식은 5를 항상 위로 올리기 때문(away from zero)에 여기서 숫자가 원래 올리지 않았을 때 보다 오차가 커지는 일이 많아집니다. 그리고 잘 생각해 보면 어딘가 공평하지 않은 구석이 있다는 것을 느낄 수 있습니다.
대신 뱅커스 라운딩처럼 짝수쪽으로 수렴하게 해서 조금은 더 공평해집니다. 그리고 이 방식이 오차가 덜 발생한다는 것은 오래전에 여러가지 방법과 실험을 통해 증명되었다고 합니다.
그 외의 반올림 방식
위키피디아의 rounding 페이지를 보면 반올림(rounding)방식이 상당히 많다는 것을 보고 놀랄 수 있습니다. 반올림 문제는 메소포타미아에도 기록이 남아 있는 오래된 문제라고 되어 있습니다. 그리고 뱅커스 라운딩이라고 불리는 half to even 방식은 1940년도 나온 것이라고 적혀 있습니다.
뱅커스 라운딩을 기본으로 채택해서 제공하는 컴퓨터 언어나 소프트웨어가 생각보다 좀 많습니다.
R, Python3과 같은 것들이 그렇습니다. 그 외의 랭귀지도 꽤 많습니다. Excel과 RDBMS 같은 소프트웨어의 반올림 함수는 대부분 우리가 아는 “사사오입”으로 되어 있습니다. 그러다보니 행수가 많은 데이터에서 나누기, 곱하기 같은 것들이 여러번 반복하고 그 결과를 모두 합한다거나 평균을 구한다거나 하면 동일한 데이터를 가지고 계산을 해도 사용하는 컴퓨터 언어나 툴에 따라 양쪽의 결과값에 미묘한 차이가 발생합니다.
즉, round함수의 방식이 다른 것을 각각 따로 어떤 데이터의 사칙 연산을 하면서 반올림이 섞인 계산을 반복하는 경우에는 양쪽에서 똑같이 계산해도 round의 방식으로 인해 서로 결과값이 안맞는 문제가 발생합니다. 이때 정합성 오류가 부동소숫점 연산 문제나 반올림 방식의 차이로 인한 문제라는 것을 알면 그것은 해결하기도 어렵고 원인을 알면 오차를 감수하고 넘어갈 수도 있지만, 그것을 모르면 오차가 어디서 발생했는지 원인를 찾기 위해서 시간을 허비하게 됩니다.
버그인지 계산을 잘못한 것인지…
그래서 차이가 있다는 것을 알고 있는 것이 좋습니다. 물론 뱅커스 라운딩을 기본으로 채택한 것들은 별도로 사사오입을 지원하는 함수를 따로 제공하는 것이 많습니다. (아닌 것도 있는데 그럴 때는 구현해야 합니다)
용어 확인을 위해서 영어사전을 찾아 보시면 내간법/내삽법/보간법이라고 나옵니다. 뭔가 다소 괴기스러운 어감인데 (^^;) 보신적이 없다면 어감상으로는 뭔가 내부에서 간섭을 하거나 삽입하는 어떤것들이 연상될 것 같습니다.
내삽법 관련된 알고리즘을 찾다가 다시 당분간 이쪽분야를 할 일이 없어질 것 같아서 전에 찾아놓은 자료를 우선 아는데까지만 적어 놓으려고 합니다.
그래서 그냥 찾아 놓은 기법들 소개 정도입니다.
Interpolation(내간법)이라는 용어를 흔히 볼 수 있는 곳은
스크립트 랭귀지같은 것들중에 변수명을 문자열에 삽입해서 대치시키는 것.
이것은 coercing 이라고도 하는데 용어가 좀 다양하게 쓰입니다. “blah $varialbe blah” 요런거입니다. PHP, Perl등의 언어에서 쉽게 볼 수 있는데 별로 중요하지 않습니다.
데이터 분석에서 관측되지 않은 지점의 데이터를 추정하는 방법
당연히 이 포스트에서는 두번째입니다.
(아래 플롯 참조)
내간법은 관측치(Observation)가 없는 부분의 데이터를 관측치(Observation)를 이용해서 얼추 추정해서 때려 맞추는 것인데요. 대부분 현실적으로 관측을 모두 다 할 수 없어 중요한 부분만 관측하고 나머지는 추정을 해야 하는 경우에 쓰입니다.
세상은 우리의 상상만큼 그렇게 만만하지 않은 것 같아요. ^^
보통 공간통계(Geo-Spatial Analysis) 분야에서 쉽게 찾아 볼 수 있는데요.
활용에 대한 대략적인 예시는 이런 것들입니다.
전국의 모든 지점의 온도나 습도, 공기오염도 등을 다 측정할 수 없으므로 적당히 중간중간 중요한 지점을 측정하고 나머지는 보정해서 때려 맞출때
제조업등에서 불량 검사를 할 때 특정 판에서 온도 측정을 모두 할 수 없으므로 군데군데 하고 빈곳은 추정할 때
최근에는 IoT 스마트헬스케어 같은 곳에서 건물이나 집안의 온도나 습도에 대한 분포를 알고 싶은데 바닥에 센서를 죄다 깔아 놓을 수 없으니 적당한 곳만 측정하고 나머지는 때려 맞출때도 사용합니다.
사실 이것 때문에 살펴보게 된 것입니다만 그래서 어떤 방법들이 있나 봤더니 굉장히 많더군요
Regression Model (회귀 모델)
회귀 모델도 내간법에 들어갑니다.
생각해보니 그러네요. 회귀 모델도 결국 관측치도 미관측 데이터를 추정하는 것이니 그쪽으로 보면 그 분류가 맞습니다. 단 공간분석에는 적합하지 않으니 쓰지 말라는 말도 있습니다. (물론 쓰는 사람들도 있습니다)
Kernel Density Estimation (커널밀도추정)
패턴 인식이나 기계 학습 책을 보셨거나 관련된 일을 하신다면 커브피팅(curve-fitting)이나 커널밀도추정에 대해서 보신적이 있을 텐데요.
이것도 내간법으로 넣습니다.
커널 밀도 추정은 다차원 공간에서 씨알(데이터)을 하나 이상 머금은 다차원 깍두기(커널)를 만들고 깍두기를 스무딩해서 매끄럽게 만들어 밀도를 추정하는 방법입니다.
보통 2차원, 3차원까지를 많이합니다. 히스토그램의 구체화된 형태라고 할 수 있습니다. 공간 분석에서도 사용하긴 하지만 많이 사용하지는 않는 것 같습니다.
Inverse Distance Weighted Interpolation
해석을 하면 많이 어색하지만 역거리내삽법 또는 거리 반비례 가중치 내삽법등으로 바꿀 수 있을텐데 보통 IDW라고 통칭합니다. GIS나 Geo-Spatial에서 흔히 볼 수 있는 내삽법입니다. 그냥 거리가 멀어질 수록 영향을 덜 받는다입니다.
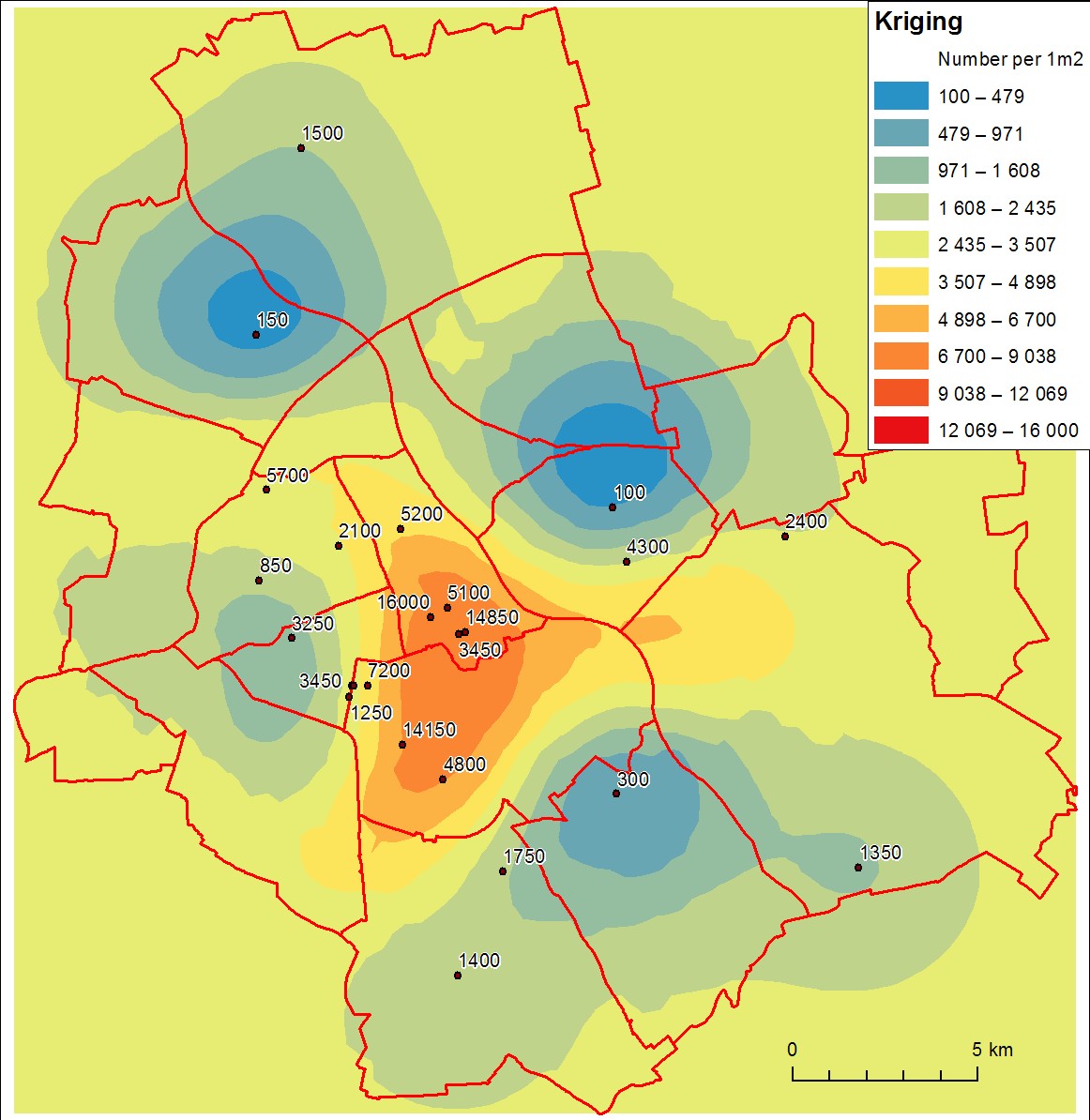
Kriging (그리깅 격자법)
만든 사람이 이름이 Krige여서 Kriging라고 합니다. 크리깅 또는 그리깅이라고 읽는데 우리말의 김치의 ㄱ과 같은 발음인 것 같습니다. 이름도 이상하지만 이건 상당히 복잡한데요. Spatial Analysis 책을 들여다보면 분산도(Variogram) 부터 공간자기상관(Spatial Autocorrelation) 같은 말부터 Semivariogram같은 비전문가에게는 무척 생소한 용어가 나오고 알고리즘을 따라 내려가다보면 결국 최적화 문제로 라그랑지 승법이 나옵니다.
성능이 굉장히 좋다고 알려져 있어서 대부분 GIS나 Geo-Spatial에서는 항상 언급이 됩니다. IDW보다는 수학적, 통계학적으로 기반 이론이 훨씬 그럴싸하기 때문에 굉장히 자주 사용하는데 역시 좋은 만큼 안쪽은 쉽게 설명하기에는 상당히 복잡합니다.
그리고 크리깅은 다시 Simple Kriging, Universal Kriging, Ordinary Kriging 등으로 나뉩니다.
보간법 중에는 Kriging이 끝판왕쯤 되는 것 같습니다. 추가로 크리깅은 예측값에 대한 에러를 추정하는 것이 가능하다고 되어 있습니다.
조금 신기하네요. 요건 나중에 따로 정리를 시도해 보겠습니다. (너무 어려워서…)
보간법은 이외에도 무수히 많습니다. K-NN도 사용을 하구요 당췌 뭐가 뭔지 모를 정도로 많아서 혼란스러운데 역시 가끔은 다른 쪽에서는 뭘하고 있는지 살펴보는 것도 중요한 것 같습니다.