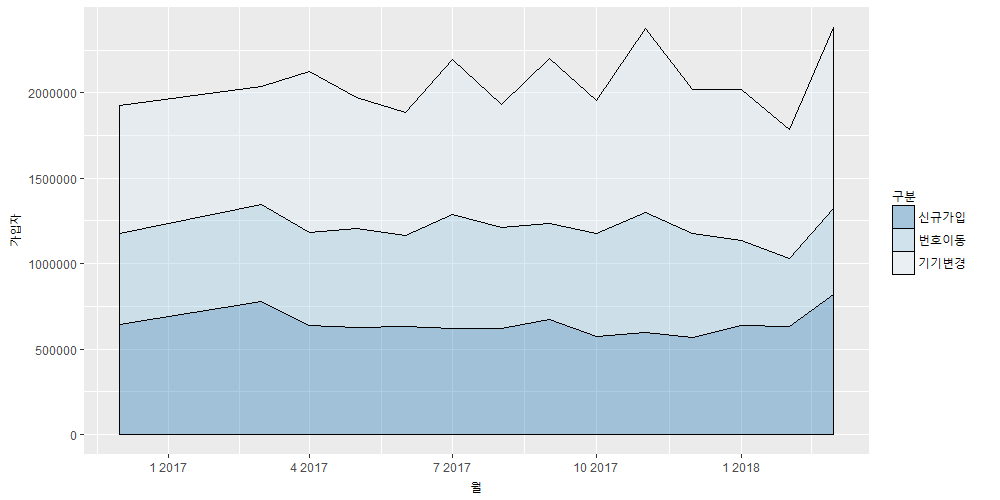
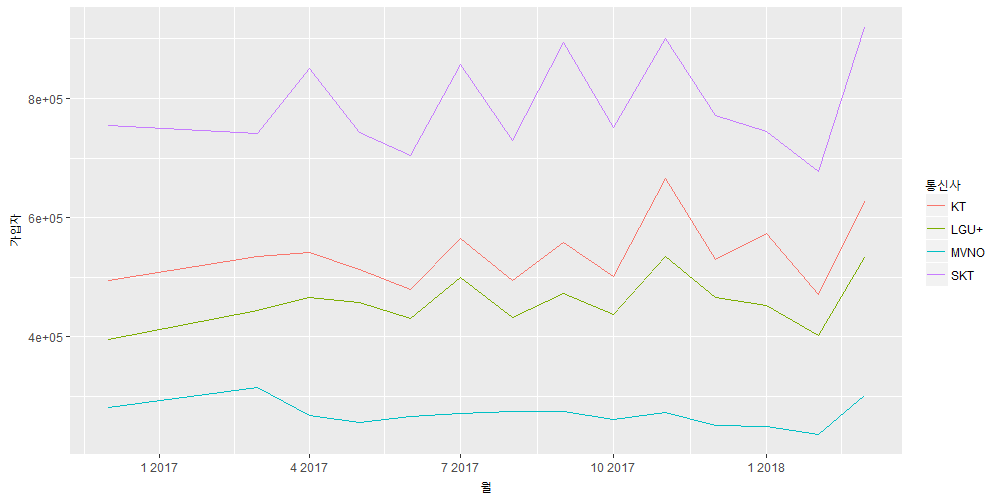
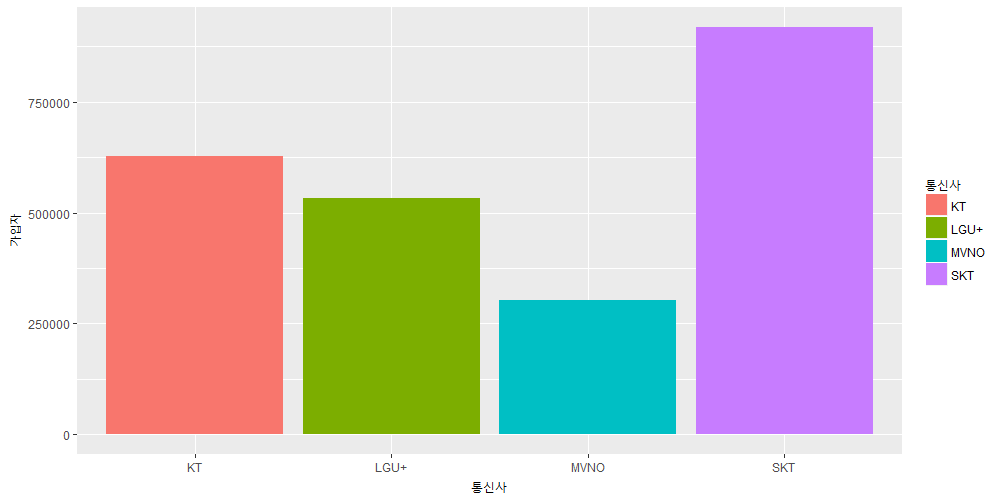
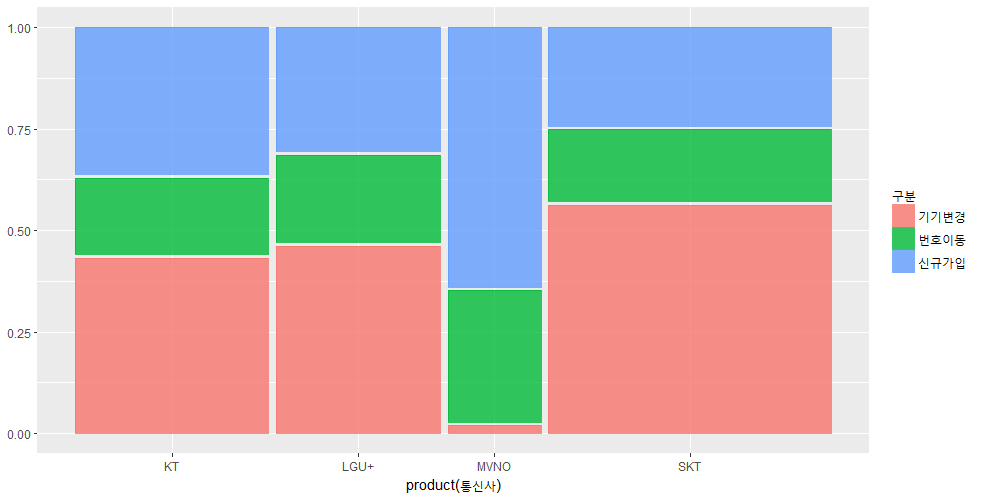
유클리디안 유사도라고도 하는데 원래 유클리디안 거리(Euclidean distance)라고 말하는 것이 맞는 것 같습니다. 유클리디안 유사도는 다소 이상한 단어의 조합이라는 생각이 듭니다. 하지만 유클리디안 유사도라는 말도 많이 통용되므로 이 포스트에서도 그냥 그렇게 하기로 하겠습니다.
유클리디안 유사도(Euclidean similarity)는 유클리디안 거리를 구해서 두 벡터의 유사도로 사용한다는 뜻입니다.
유클리디안 거리는 직선 거리다
유클리디안 거리는 기하학적으로 볼 때 두 점의 직선거리를 구하는 것입니다. 또는 선형대수에서 주로 다루는 벡터 스페이스(Vector space)라고 불리는 선형 공간에서도 동일하게 최단 거리를 구하는 것을 말합니다.
코사인 유사도를 설명할 때 언급한 적이 있습니다만 유사도는 2개의 데이터만 가지고 계산해서 결과값을 뽑아내도 그것만으로는 아무짝에도 쓸모가 없습니다.
세상에 사람이 둘 만 남았다면 두 사람은 서로 닮은 걸까요? 안 닮은 걸까요? 모릅니다.
유사도는 다음과 같은 방식으로 주로 사용합니다.
- 여러 개의 데이터에서 주어진 것과 가장 가까운 것이 어떤것인가?
- 여러 개의 데이터에서 가장 가까운 것들끼리 묶어보자
유클리디안 거리는 데이터마이닝이나 기계학습에 익숙하시다면 K-means (K민즈, K중심값, K평균 이라고 번역합니다) 같은 것에서 사용하는 것을 본 적이 있을 것입니다. 유사도라는 것이 사실은 거리를 측정하는 방법(distance measurement)일 수 밖에 없습니다. 거리를 측정하는 방법을 어떤 것을 쓰느냐에 따라 이름을 무슨 무슨 유사도 이렇게 “유사도”라는 단어를 붙여서 부릅니다.
유클리디안 거리 구하기
유클리디안 거리를 구하는 방법은 간단하고 매우 쉽습니다.
피타고라스 정리를 알면 됩니다.
직각삼각형의 빗변의 길이를 구하는 것입니다.
위키피디아를 보면 거기에 그림을 아래와 같이 넣어놓고 설명해 놨습니다.

간단 한 수식이 있지만 그림으로 보니 눈이 아프군요.
그림에서 p와 q의 유클리디안 거리는 p와 q의 직선거리를 구하면 되는 것이고 가운데 만들어진 삼각형이 직각삼각형이니까 피타고라스 정리를 쓰면 빗변의 길이, 즉 대각선의 길이를 구할 수 있습니다. 이 대각선의 길이가 유클리디안 거리입니다.
결론은 삼각형의 빗변의 길이를 계산하면 됩니다.
참고로 피타고라스 정리가 3차원 이사의 고차원에서도 되는 건지 헷갈릴 수 있겠습니다. 당연히 3차원 이상에서도 적용이 됩니다. 3차원, 4차원, 5차원, …, R차원 다 됩니다.
수학자들이 증명해 놓은 것이 있습니다. 그냥 믿고 쓰시면 됩니다.
5차원인 경우를 예를 들어서 설명하면
아래와 같이 2개의 5차원 벡터가 있다고 하고
a = (1, 2, 3, 4, 5)
b = (2, 3, 4, 5, 6)
벡터의 멤버수가 5개씩이므로 둘 다 5차원 벡터입니다. 차원이 다르면 안됩니다. 맞춰 줘야지요.
각각 차원(축)을 맞춰서 순서때로 빼준 다음에 제곱해서 더한 다음에 루트를 씌우면 됩니다.
1번째 차원: 1 – 2를 계산해서 제곱 = 1
2번째 차원: 2 – 3을 계산해서 제곱 = 1
3번째 차원: 3 – 4를 계산해서 제곱 = 1
4번째 차원: 4 – 5를 계산해서 제곱 = 1
5번째 차원: 5 – 6를 계산해서 제곱 = 1
다 더한 다음에 루트
sqrt(1 + 1 + 1 + 1 + 1)
답은 2.236068 입니다.
R코드로는 이렇게 하면 됩니다.
a_vector <- c(1, 2, 3, 4, 5) b_vector <- c(2, 3, 4, 5, 6) dist(rbind(a_vector, b_vector))
추가로 유클리디안 거리는 양적인 것을 기반으로 하는 것이라서 축의 스케일이 맞지 않으면 이상한 측정이 됩니다. 축의 스케일을 맞춰야 할지 말아야 할지는 그때 그때 다릅니다.
이런 말이 나오면 항상 골치만 아픕니다만 어쨌든 뭐든 쉽게 쓸 수 있는 것은 없는 것 같습니다.
예를 들면 이런 경우입니다.
a = (1, 2, 3000000, 4, 5)
b = (2, 3, 4000000, 5, 6)
c = (3, 4, 5000000, 6, 7)
3번째 차원, 3번째 축의 값에 의해 가장 큰 영향을 받습니다. 다른 차원의 값들은 구실을 못하게 됩니다.
기회가 되면 다른 포스트에 스케일을 맞추는 여러가지 방법도 적어 보겠습니다.