BigQuery 테이블에 어떤 필드에 JSON 문자열이 들어 있고 이 JSON 문자열에서 어떤 키에 해당하는 값을 가져오는 간단한 쿼리 스니펫입니다.
들어있는 JSON 문자열의 포맷이 큰 문제가 없으면 괜찮은데 아닌 경우가 있습니다. 그래서 간단하게 쿼리를 돌려서 테스트 해봤습니다.
BigQuery에 JSON 문자열에서 원하는 키에 해당하는 값을 가져오는 샘플 쿼리입니다.
간단한 테스트를 하는데 테이블을 만드는 것이 귀찮으니 JSON 문자열 여러 개를 array로 만들고 UNNEST로 꺼내서 합니다. 다른 데이터베이스에서는 UNION ALL을 하고 INLINE VIEW로 묶어서 꺼내거나 LATERAL VIEW를 쓰면 됩니다.
SELECT json_str AS json_str
, JSON_EXTRACT_SCALAR(json_str, '$.prob') AS prob_scala
, JSON_EXTRACT_SCALAR(json_str, '$.bin') AS bin_scala
, JSON_EXTRACT(json_str, '$.prob') AS prob_str
, JSON_EXTRACT(json_str, '$.bin') AS bin_str
FROM UNNEST([
'{}',
'{"prob":"0.413656","bin":"0"}',
'{"prob":"0.010643","bin":"3"}',
'{"prob":"0.000114","bin":"2"}',
'{"prob":"0.802312","bin":"NULL"}',
'{"prob":"NULL","bin":"NULL"}',
'{"prob":"NULL","bin":"65"}',
'{prob:"0.627363",bin:23}',
'{\'prob\':0.27372,\'bin\':45}'
]) AS json_str
;
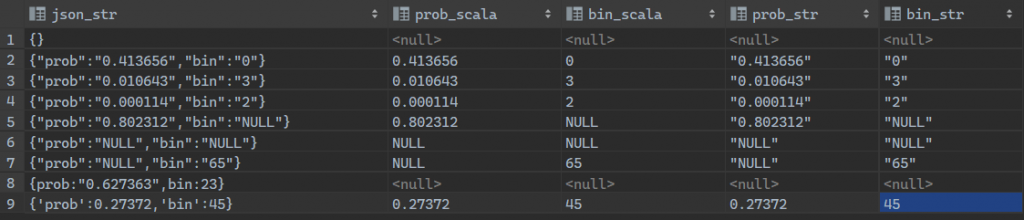
결과를 TSV형태로 뽑아보면 다음과 같습니다.
json_str prob_scala bin_scala prob_str bin_str
{}
{"prob":"0.413656","bin":"0"} 0.413656 0 "0.413656" "0"
{"prob":"0.010643","bin":"3"} 0.010643 3 "0.010643" "3"
{"prob":"0.000114","bin":"2"} 0.000114 2 "0.000114" "2"
{"prob":"0.802312","bin":"NULL"} 0.802312 NULL "0.802312" "NULL"
{"prob":"NULL","bin":"NULL"} NULL NULL "NULL" "NULL"
{"prob":"NULL","bin":"65"} NULL 65 "NULL" "65"
{prob:"0.627363",bin:23}
{'prob':0.27372,'bin':45} 0.27372 45 0.27372 45저렇게 보면 눈에 잘 안 들어오는데 이렇게 보면 실제 NULL값과 “NULL”이라는 문자열 그리고 key가 따옴표 또는 큰타옴표로 묶여 있지 않는 것들이 어떻게 처리되는지 볼 수 있습니다.
위의 결과는 DataGrip에서 결과를 확인한 것입니다.
결과를 자세히 보시면 알겠지만 사용할 때 주의할 점은 이렇습니다.
- 우선 JSON의 안쪽에 키(key)는 큰따옴표 또는 작은따옴표로 묶여 있어야 합니다.
- JSON_EXTRACT는 키에 해당하는 값을 통째로 다 문자열로 가져옵니다
- JSON_EXTRACT_SCALA는 키에 해당하는 값에서 큰따옴표, 작은따옴표를 없애고 알맹이만 꺼내 옵니다.