
요약
XGboost는 기계학습에서 사용하는 결정 트리(Decision Tree)라는 계열의 알고리즘 중 하나입니다. 중요한 특징으로는 분산 컴퓨팅으로 기계학습 모델을 빌드 할 수 있습니다.
즉 어려대의 서버로 대량의 학습데이터를 사용해서 결정트리 기계학습 모델을 만들 수 있게 해주는 기계학습 프레임워크(알고리즘)입니다.
결정 트리 (Decision Tree)
결정나무라고도 번역하는데 이게 느낌이 너무 이상해서 대부분 디씨젼트리 또는 결정트리라고 부릅니다.
결정트리 (Decision Tree)의 계보는 CART부터 시작해서 밑에 그림과 같습니다. 뒤에 LightGBM아 몇개가 더 있습니다만 XGboost까지의 계보는 저렇습니다.
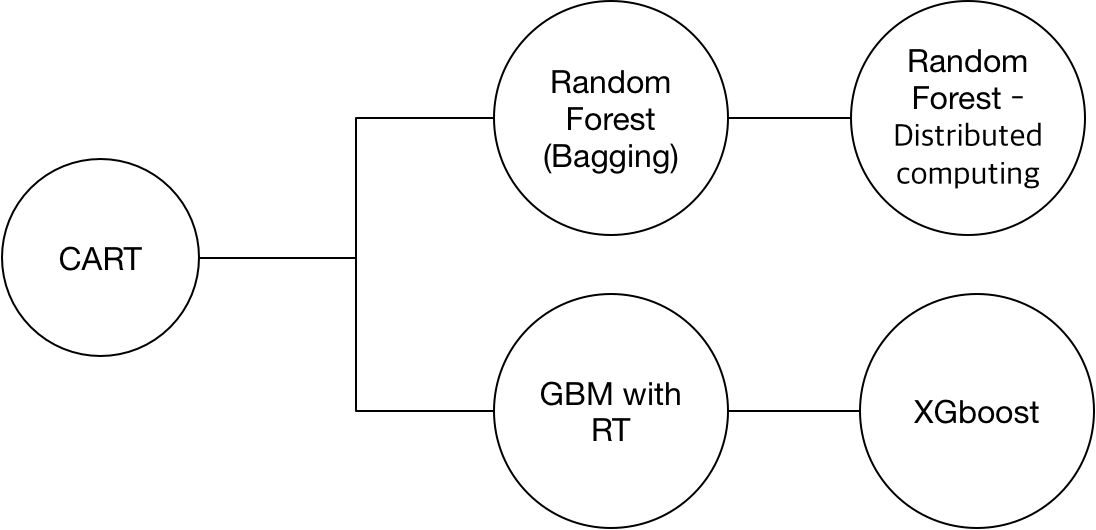
여기서 아마 역사적으로 가장 잘 알려진 것은 “랜덤포레스트”일 것입니다.
랜럼포레스는 결정트리에 배깅 기법을 추가한 것이고
GBM은 결정트리에 부스팅 기법을 추가한 것입니다.
GBM은 분류 알고리즘이라면 어떤 알고리즘이라도 사용할 수 있지만 결정트리가 가장 쓰기 편하고 좋기 때문에 GBM은 결정트리를 주로 씁니다.
XGBoost: A Scalable Tree Boosting System
개요
- XGBoost = eXtream Gradient Boosting
- Gradient Boosted Decision Tree의 분산 컴퓨팅을 위한 새 구현체
- 정확히 설명하면 GBM(Gradient Boosting Machine)의 분산 환경을 구현체
잘 알려지지 않았지만 GBRT (Gradient Boosting Decision Tree)는 정말 성능이 좋은 알고리즘이지만 모델 빌드속도가 매우 느리고 분산 노드를 이용해서 빌드 속도를 단축시키는 것이 가능하지 않다는 문제가 있습니다. GBRT는 정확도를 쥐어짜듯이 끌어내면서도 과적합(오버피팅)이 심하게 되지 않는 장점이 있습니다.
GBRT의 문제점은 학습데이터가 많아지고 자질(feature)가 많아질 수록 빌드속도가 늘어나고 한대의 컴퓨터에서 처리할 수 없는 메모리를 사용해야 하면 빌드를 하지 못합니다.
XGboost는 그 문제를 해결해놓은 것입니다.
이 문제를 해결했기 때문에 GBRT를 이용해서 대량의 학습데이터로 성능을 최대한 뽑아내는 모델을 빌드할 수 있게 되었습니다.
논문 Paper
읽어보면 좋습니다만 좀 어렵습니다.
https://arxiv.org/abs/1603.02754
유용한 정보
XGboost는 monothonic 제약을 지원합니다. 예측값이 항상 과거 보다는 미래의 값이 크거나 같아야 하는 경우를 말합니다.
- XGboost monotonic constraint
사용상 문제 Issue
아직 몇 가지 문제도 있고 그렇습니다만 일반적으로 쓰는 데는 큰 문제가 없습니다.
- XGboost python package in pypi has a critical bug. so python package has to be installed from github source directly.
그리고 카테고리 변수를 사용하지 못하는 큰 문제가 있습니다.
참조
- https://arxiv.org/pdf/1603.02754.pdf
- http://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
- https://xgboost.readthedocs.io/en/latest/
다른 자료들도 참조하세요.