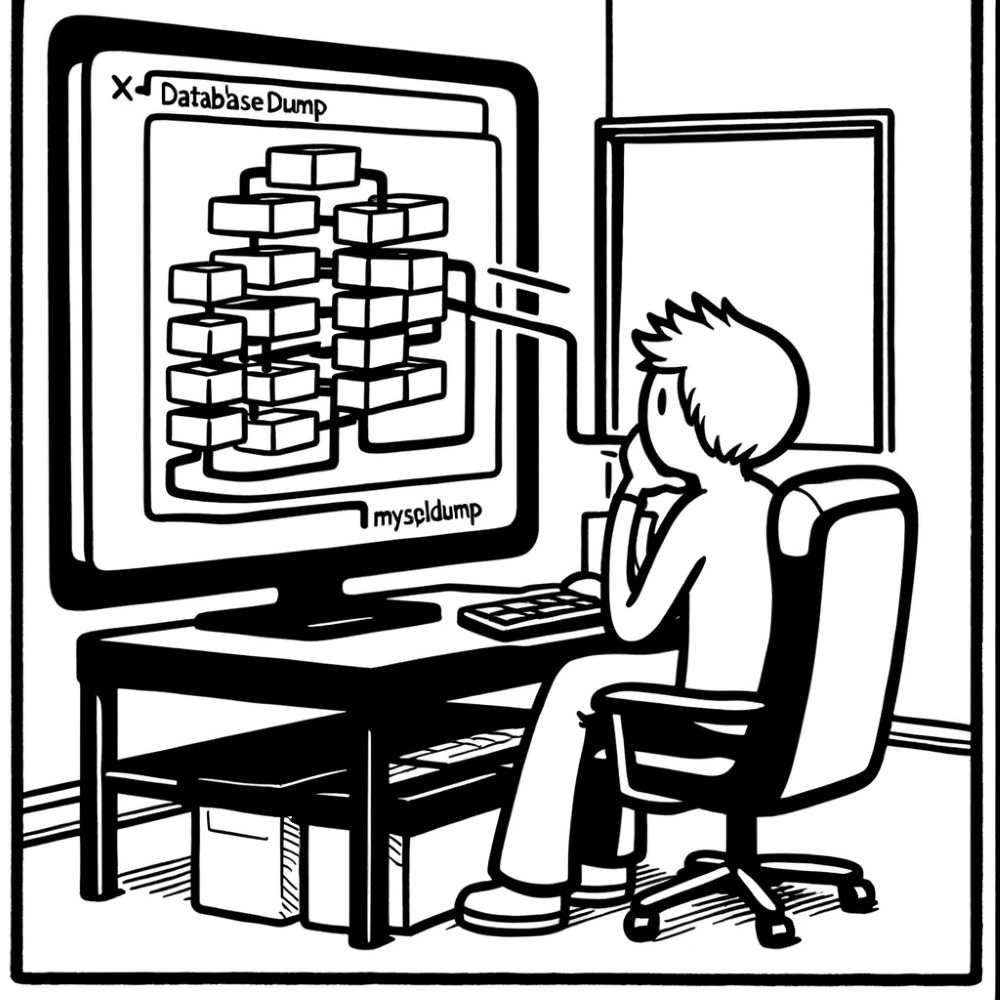
MBC에서 제공하는 2024 총선 시각화 페이지의 링크
전달력이 있는 잘 구성된 시각화의 예라고 할 수 있습니다.
여론M의 데이터 저널리즘관련 콘텐츠는 꽤 잘되어 있는 편입니다.
MBC에서 제공하는 2024 총선 시각화 페이지의 링크
전달력이 있는 잘 구성된 시각화의 예라고 할 수 있습니다.
여론M의 데이터 저널리즘관련 콘텐츠는 꽤 잘되어 있는 편입니다.

CTR은 Click Through Rate 입니다.
클릭수/노출수x100으로 계산하는데
짧게 말하면 노출대비 클릭수의 비율이라고 할 수 있습니다.
검색결과 또는 추천시스템의 성과를 확인하기 위한 가장 기본적인 지표로 많이 쓰입니다.
본론으로 들어가서
광고 노출, 검색 결과를 잘 조절해서 CTR을 획기적으로 올리는 방법은
별로 없습니다.
보통 제안하는 상품이나 검색 결과가 오디언스(사용자 또는 고객)의 관심을 끌지 못하면 CTR은 떨어집니다. 관심이 없으면 클릭을 하지 않기 때문입니다.
이커머스에서도 CTR은 매우 중요합니다. 이커머스에서는 추천상품 모듈이 있어서 검색이나 특정 상품을 볼 때 다른 추천 상품을 제안해서 구매를 유도합니다. 그 외에 검색해서 나오는 상품들도 사실상 추천이라고 할 수 있습니다. 검색 결과도 원칙적으로는 추천입니다.
추천시스템(Recommendation system)을 업그레이드 해서 개선에 성공한다면, 그리고 CTR을 올리면 과연 매출이 올라가느냐?라는 의문을 가질 수 있습니다.
이게 정말 그러냐는 것인데
답: 그럴 수도 있지만 아닌 경우가 더 많습니다.
우선 개발자 또는 ML엔지니어가 가장 많이 착각하는 것이 “CTR을 올리면 당연히 매출도 올라가겠지” 라고 단정해서 짐작하는 것입니다.
하지만 이 짐작은 그 자체로는 과학적 근거가 없습니다.
게다가 CTR은 비즈니스 업종, 제품 카테고리(품목), 시즌에 따라서 각기 다른 양상을 보입니다.
매우 복잡하지요.
더 구체적으로 설명하면
상품 노출 후 구매까지의 단계는
추천 상품 노출 -> 클릭 -> 구매
로 됩니다.
그리고 클릭율과 전환율의 정의를 보면
노출 -> 클릭으로 가는 비율을 계산한 것이 CTR (클릭율)
클릭 -> 구매로 가는 비율을 계산한 것이 CVR (전환율)
다시 원래의 질문으로 돌아가서 CTR을 높이면 매출이 정말 올라가느냐?가 맞으려면 CTR을 올리고 CVR이 그대로 이거나 증가해야 합니다.
CTR이 많이 올라갔으면 CVR은 오히려 조금 떨어져도 됩니다. 높은 CTR이 CVR의 감소를 만회해 줍니다.
하지만
모델을 개선해서 CTR을 올렸는데 CVR이 줄어드는 경우가 꽤 많이 생깁니다.
CVR과 CTR이 음의 상관관계를 가지는 경우가 많기 때문입니다.
이것 때문에 분명 CTR은 높아졌는데 정작 매출이 늘지 않게 됩니다.
그래서 이것이 클릭예측모델(클릭 모델)을 만든 후에 구매예측모델을 만드는 발단이 되기도 합니다. 구매예측모델은 더 만들기 어렵고 잘 안됩니다. 이것은 나중에 따로 얘기하기로 합니다.
마케팅과 행동과학 측면에서 생각하는 것을 고려해야 합니다.
CTR이 오른다는 것은 사람들이 추천한 제품에 관심을 많이 보였다는 것입니다.
그런데
사람들에게 많은 관심을 받는 제품이 반드시 잘 팔리는 제품은 아닙니다.
예를 들어
“휘어지는 4K 200인치 TV” 같은 것은 많은 사람들에게 관심을 갖도록 할 수 있지만
구매하는 사람은 많지 않습니다.
“생글생글 생수” 이런 생수는 사람들의 관심을 끄는 제품이 아니라서 CTR은 낮지만
CVR은 매우 높은 제품입니다.
TV는 고관여제품이고 생수는 저관여제품입니다.
고관여제품: 사는데 고민을 많이 하고 비싼 제품. 구매 후 실패하면 위험 부담이 큰 제품
저관여제품: 사는데 고민을 적거 하고 싼제품. 구매 후 실패를 걱정하지 않는 제품
사람들은 생수에 대해서 잘 알고 있고 동일한 제폼이나 유사한 제품을 반복해서 구매합니다.
그래서 이런 저관여제품의 구매는 망설임이 없이 구매합니다.
이외에도 여러 문제가 있다.
그래서 추천시스템의 성과를 단순히 CTR로 측정해서는 안되고 추천해서 사람들이 클릭한 것만으로 모델의 가치평가를 하게 되면 모델을 론칭하고 나서 비즈니스에서는 실제 개선이 없는 상황을 맞이 하게 됩니다.
추천시스템의 모델링에 집착해서 기계학습 모델의 개선에만 몰두하는 곳이 매우 많은데
위와 같이 실제 비용효율이 나지 않는 경우를 많이 보았습니다.
대부분의 모델을 새 알고리즘으로 교체하거나 피처 엔지니어링을 통해 개선하고 나면 아주 적은 CTR의 개선을 볼 수 있겠지만 전체 매출에는 통계적으로 무의미한 미미한 증가만 얻게 됩니다.
비용효율이 안나오게 되고 이런 일이 반복되면 비즈니스 담당자로부터 모델과 기술자는 신뢰를 잃게 됩니다.
무작정 CTR을 올리는 모델을 잘 만들기만 하면 비즈니스는 대박이 나고 나는 스타가 될 수 있을꺼야 라고 생각하는 MLE나 데이터과학자가 많습니다.
해보면 알겠지만
세상은 그렇게 만만하지 않습니다.

Docker를 사용하는 것이 이미 일반화되었지만 가끔 코맨드의 기능을 명확하게 기억하지 못할때가 있다.
stop과 down의 차이인데 다음과 같다.
도커이미지를 구성할 때 down 명령을 사용할 경우를 대비해서 설명에 네트워크 설정에 대한 것도 문서에 자세히 기록할 필요가 있다. 익숙하다고 방심하면 빠뜨려서 문제를 만드는 경우가 많아진다.

LLM은
기술통계와 같은 설명기반의 분석은 할 수 있습니다.
연과분석과 같은 원인을 파악하고 통찰을 얻는 것은 할 수 없습니다.
즉 LLM은 데이터분석을 할 수 없다고 할 수 있습니다.
데이터분석가들이 말하는 능동적인 고급데이터 분석에 대한 것을 말한다면 그렇습니다.
데이터분석은 결과물에 따라 2가지로 나눌 수 있는데
LLM은 인과분석과 같은 논리적 사고를 할 수 있게 고안된 것이 내부에 없습니다.
대형 뉴럴네트워크에서 대량의 학습이 되면 마치 인과추론과 사고를 하는 것 처럼 만들 수 있는데
그것은 하는 것 처럼 보이는 것이지 진짜 하는 것이 아닙니다.
아직 LLM이 사고를 하고 데이터분석을 한다는 것이 증명된 적도 없습니다.
그래서 LLM은 데이터를 넣어주는 것 만으로는 인과분석과 같은 고급데이터 분석을 하지 못합니다.
다만 프롬프트를 단계적으로 입력하거나 절차형으로 넣어서 (CoT) 비슷하게 할 수는 있지만
인간과 같은 깊은 고찰에서 나오는 결론과 답을 내주지는 않습니다.
ChatGPT의 코드인터프리터와 같은 별도의 모듈을 이용하면 하는 것처럼 보이도록 하는게 가능하지만 근본적으로 데이터 분석을 하는 것은 아닙니다.
LLM은 아직 스스로 고뇌하고 고민하는 사고를 하지 못합니다.
데이터분석의 결과물은 인간의 깊은 고민과 사고의 결과물입니다.
mysqldump를 하면 DB에 lock를 걸게 된다. 기본 설정이 그렇게 되어 있다.
서비스 운영중인 데이터베이스에 그런 것을 하면 큰 문제가 생긴다.
mysqldump를 할 때 lock을 걸지 않도록 하는 옵션을 해야 한다.
mysqldump를 할 때 자주하는 것이 아니라서 실수하기 쉬운데 다음과 같이 옵션을 주고 처리할 수 있다.
mysqldump --skip-add-locks --skip-lock-tables db table > dump.sql덤프하는 중에도 다른 세션에서 insert, update, delete 가능하다.
mysqldump --single-transaction db table > dump.sql덤프하는 중에도 다른 세션에서 insert, update, delete 가능하다.
mysqldump --lock-tables db table > dump.sql덤프하는 중에 다른 세션에서 insert, update, delete 불가능하다.