If you want extract a domain from provided URL strings in BigQuery.
It’s very easy. You can use net.Host function.
WITH
examples AS (
SELECT "https://some.domain.com/path?query=param#hash" AS example
UNION ALL
SELECT "some.domain.com/path?query=param#hash" AS example)
SELECT
NET.HOST(example)
FROM
examples
MISCONF Redis is configured to save RDB snapshots, but it’s currently unable to persist to disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.
해결책은
다음과 같이 해결할 수도 있고
config set stop-writes-on-bgsave-error no
다음과 같이 해결할 수도 있다
CONFIG SET dir /tmp/some/directory/other/than/var
CONFIG SET dbfilename temp.rdb
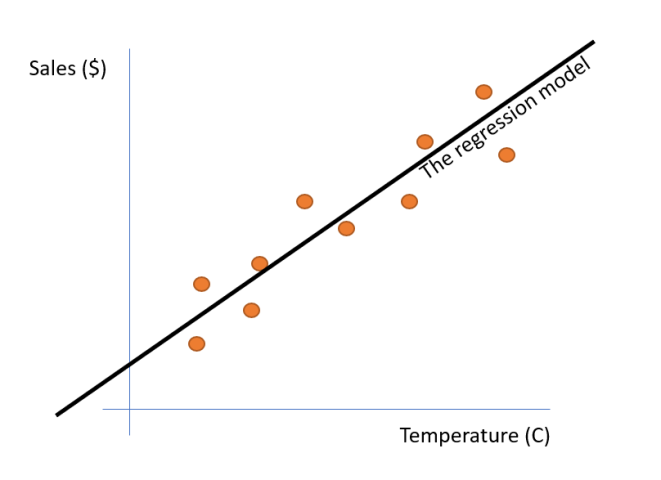
시계열 데이터는 시간의 순서대로 측정된 데이터이기 때문에 시간에 따른 순서가 있습니다. 일반적인 선형 회귀모형인 최소제곱법을 사용할 경우, 예측값과 실제값의 차이를 제곱한 값을 최소화하는 것이 목표입니다. 이러한 최소제곱법은 잔차의 분포가 정규분포를 이루는 경우에만 적용됩니다. 시계열 데이터의 경우 잔차의 분포가 정규분포를 이루지 않을 수 있기 때문에 최소제곱법을 적용할 수 없습니다.
그렇기 때문에 시계열 데이터에서는 최소제곱법을 사용하는 선형 회귀모형 대신에, 잔차의 분포가 정규분포를 이루지 않더라도 적용할 수 있는 모형을 사용합니다. 이러한 모형에는 시계열 잔차의 자기상관계수가 일정한 수준 이하인 자기상관 선형 모형 (ARIMA), 시계열 잔차가 정규분포를 이루지 않는 경우에 적용할 수 있는 시계열 잔차의 분포가 일정한 수준 이하인 자기상관 선형 모형(ARIMAX) 등이 있습니다.
또한, 시계열 데이터의 경우 자기상관이 있을 수 있기 때문에 일반적인 선형 회귀모형과는 달리 자기상관을 제거하기 위해 차분(differencing) 작업을 수행할 수 있습니다. 차분은 시계열 데이터의 차이값(difference)을 사용하여 자기상관을 제거하는 과정입니다. 이렇게 차분한 시계열 데이터에 선형 회귀모형을 적용할 수 있습니다.
시계열 데이터에 선형 회귀모형을 적용하지 않을 수도 있습니다. 이 경우 시계열 데이터의 특성을 잘 반영할 수 있는 모형을 선택해야 합니다. 예를 들어, 시계열 데이터가 점선으로 그려지고 추세가 있는 경우 선형 회귀모형이 적합하지 않을 수 있습니다. 이 경우에는 추세를 반영할 수 있는 적절한 모형을 선택할 수 있습니다. 예를 들어 추세가 있는 시계열 데이터에는 추세를 고려한 선형 회귀모형인 전방산정모형(forward-looking regression model)과 지수선형회귀모형(exponential linear regression model) 등이 적용될 수 있습니다.
또한, 시계열 데이터의 경우 시간에 따른 추이가 있을 수 있기 때문에 시간에 따른 추이를 반영할 수 있는 모형도 적용할 수 있습니다. 예를 들어 시계열 데이터의 경우 시간에 따른 추이가 있고, 이를 선형으로 나타낼 수 없을 경우에는 시간에 따른 추이를 나타낼 수 있는 시계열 모형인 선형 추이선형회귀모형(linear trend linear regression model)과 지수선형 추이선형회귀모형(exponential trend linear regression model) 등이 적용될 수 있습니다.
정리하자면, 시계열 데이터에는 선형 회귀모형을 적용하기 어려울 수 있는 여러가지 이유가 있습니다. 시계열 데이터의 경우 잔차의 분포가 정규분포를 이루지 않을 수 있기 때문에 최소제곱법을 적용할 수 없기 때문입니다. 또한, 시계열 데이터는 자기상관이 있을 수 있기 때문에 차분을 통해 자기상관을 제거할 수 있습니다. 이 경우 차분한 시계열 데이터에 선형 회귀모형을 적용할 수 있습니다. 또한, 시계열 데이터의 경우 추세가 있거나 시간에 따른 추이가 있을 수 있기 때문에 이를 반영할 수 있는 모형을 적용할 수도 있습니다.
데이터를 다룰 때 날짜 타입이 있는 경우에는 타임존을 항상 신경써야 합니다. 어떤 날짜타입은 타임존을 내부에 가지고 있고 어떤 타입은 그렇지 않습니다. 데이터를 추가할 때 현재 날짜 또는 시각의 타임스탬프를 자동으로 추가하는 기능을 사용할 때는 어떤 타임존으로 설정되어 있는지 확인하고 사용해야 합니다.
# getting current timezone of database system
SELECT @@global.time_zone, @@session.time_zone;
# checking difference default timezone with UTC
SELECT TIMEDIFF(NOW(), CONVERT_TZ(NOW(), @@session.time_zone, '+00:00'));
# example code for converting timezone
SELECT CONVERT_TZ(CURRENT_TIMESTAMP, '+09:00', '+00:00');