[et_pb_section][et_pb_row][et_pb_column type=”4_4″][et_pb_text]
트위터에서 만든 OpenKoreanText가 있습니다.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section][et_pb_section][et_pb_row][et_pb_column type=”4_4″][et_pb_text]
트위터에서 만든 OpenKoreanText가 있습니다.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]게임 광고에 대한 분석을 하다 보면 종종 재밌는 사실을 알 수 있습니다.
그 중에 재밌는 것은 게임 내에서의 게임 광고입니다.
모바일 게임을 설치해서 하다보면 아이템을 얻거나 다시시도를 하는 댓가로 광고를 보게하는 것이 많다. 광고 수익을 얻기 위한 것인데 게임 광고에서는 유난히 다른 게임의 광고가 많이 나옵니다.
이것은 예전에는 카니발라이제이션이라는 문제라 하지 않았던 것입니다. 즉 다른 게임의 광고를하면 사용자가 그 게임을 설치해서 하게 되고 지금 하는 게임은 하지 않기 때문입니다.
하지만 그럼에도 불구하고 최근 게임광고가 게임에 많이 보이는 이유는 다음과 같습니다.
나이키 의류 앱이 있다면 현실적으로는 어려울 수 있겠지만 여기에서 아디다스나 다른 스포츠웨어 광고를 한다면 매우 클릭율이 높을 수 있습니다.
이런 것을 이용해서 많은 버티컬 이커머스(특정 카테고리만 판매하는 쇼핑몰)나 종합 이커머스에서는 메타 쇼핑이라는 것을 하려고 비즈니스 전환을 많이 하고 있습니다.
즉 메타쇼핑같은 곳에서 어떤 카테고리 또는 여러 카테고리의 상품을 모아서 추천시스템 같은 것을 해서 잘 보여주고 광고를 한다면 일반 광고 매체보다 클릭율과 구매율이 더 높아질 가능성이 매우 큰 것입니다.
이것은 이미 메타쇼핑 또는 버티컬 쇼핑에 자주 접속하는 사용자라면 적극적으로 제품을 구매할 의향이 있다는 것이며 구매에 적극적이기 때문에 정보를 얻기 위해서 클릭에도 적극적입니다.
예를 들면 특정 육류 판매 쇼핑 앱에서 타사의 육류 상품을 판매한다면 자사의 육류가 판매되지 않을 것이기 때문에 문제가 됩니다.
이 문제를 해결하는 방법은 매우 간단합니다.
회사를 여러 개 설립해서 만든 후에 브랜드와 상표를 다르게 하고 동일한 육류를 판매하는 것입니다.
일종의 트릭이지만 잘 알려진 예로 음식배달이 있습니다.
음식배달에도 많이 사용하는 방법으로 같은 업소가 여러 음식을 다른 상호로 배달앱에 등록하는 경우입니다. 이렇게 하면 음식업체에서는 전화를 받을 화률이 매우 높아 집니다. 물론 배달앱의 검색에서 상위에 나오게 하기 위해서 광고비, 홍보비가 많이 드는 것은 별개의 문제입니다.
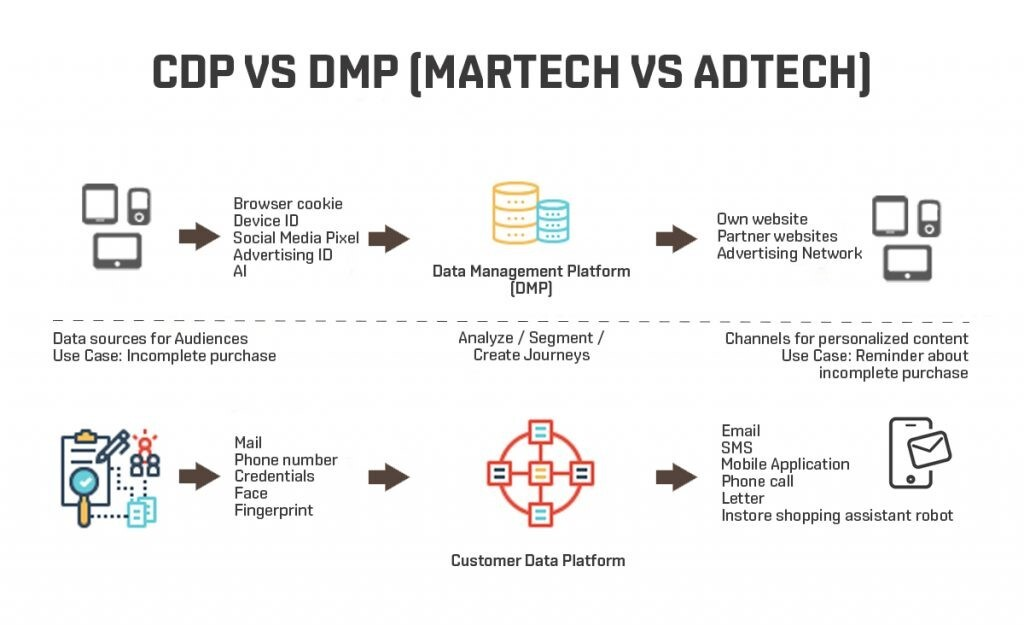
CDP는 디지털마케팅과 관련된 고객 데이터 관리 및 분석 플랫폼입니다.
여기서 말하는 고객 데이터는 주로 고객의 행적 데이터입니다.
언제 쇼핑몰에 접근하고 어떤 물건을 조회하고 샀는지와 같은 것들입니다.
자세히 말하는 CPD는 온라인쇼핑몰 같은 이커머스 비즈니스 또는 온라인 / 오프라인 비즈니스가 가능한 곳에서 자사의 몰 또는 비즈니스 플랫폼에 접속, 접근하는 고객들의 행적 데이터를 수집, 통합, 분석해서 마케팅에 활용하게 해주는 플랫폼입니다.
CDP는 유료 플랫폼을 사용하거나 자사가 직접 구축해서 사용하는데 클라우드 중에서는 Google CDP와 그 외에 몇개의 솔루션이 있습니다.
구글어낼리틱스 Google Analytics(줄여서 GA라고 부름)도 CDP의 일종이지만 CDP는 GA보다 더 세분화되고 깊은 수준의 인사이트를 얻을 수 있도록 합니다. 그리고 구글은 GA가 아닌 별도의 CDP 솔루션을 제안하고 있습니다.
https://cloud.google.com/solutions/customer-data-platform#section-2
애드테크(광고IT)에서는 DMP (Data Management Platform)이라는 것이 있는데 CDP와 유사한 개념이라서 혼동이 생길 것입니다.
다음과 같은 차이가 있습니다.
매우 밀접한 관계가 있습니다. CDP는 고객의 행적 데이터를 수집하고 분석합니다.
이런 데이터는 기계학습을 이용한 고객 세그멘테이션, 고객 상품 추천, RFM 분석과 코호트 분석을 통한 고객 리텐션에 활용할 수 있습니다.
특히 가장 유용하게 사용할 수 있는 것이 고객 이탈방지를 위한 CLV(Customer Lifetime Value)와 상품 추천입니다.
쉽게 생각하면 넷플릭스를 생각하면 됩니다.
넷플릭스는 고객들이 어떤 콘텐츠를 봤는지 패턴을 파악해서 고객들에 좋아할만하고 지식재산권 비용이 낮은 비교적 오래된 콘텐츠를 추천해서 고객들이 이탈하지 않게 만들어서 구독료로 이윤을 남깁니다.
링크 구문 앞에 느낌표!를 붙여주면 할 수 있습니다.
하지만 크기 조정을 하려면 html태그를 직접 사용해야 합니다.

<img src="./github.png" width="100px" height="50px" title="Github_Logo"/>
<img src="./github.png" width="100px" height="50px" title="Github_Logo"></img>