우분투 리눅스(Ubuntu)를 터미널로 접속해서 Copilot을 사용하려면 Neovim을 사용해야 합니다.
귀찮게 설치하지 않고 Copilot을 안쓰면 되겠지만 Copilot을 사용하면 생산성이 너무 좋기 때문에 도저히 포기할 수 없습니다.
그래서 Neovim과 Copilt을 Ubuntu에 설치하려고 하면 간단하게 되지 안고 몇가지 문제가 생깁니다.
서버 마다 이걸 반복해서 하다보니 귀찮아서 설치법을 정리했습니다.
설치순서 요약
다음은 설치 순서요약입니다.
- Node.js 12 이상 설치하기
- Neovim 0.6 이상 설치하기
- copilot.vim 설치하기
- copilot.vim 활성화하기
우선 Copilot을 쓰려면 Github 계정이 있어야 하므로 계정을 먼저 준비하세요.
그 다음의 문제가 있는데 apt로 설치를 할 수 없는 것이 Node js 12와 Neovim 0.6입니다.
apt로 설치하면 Node.js와 Neovim이 상당히 낮은 구버전이 설치됩니다. 그래서 Copilot을 쓸 수 없습니다.
다음과 같이 하면 됩니다.
설치 방법
Node.js 12 설치
먼저 Node.js 12는 다음과 같이 설치합니다.
curl -sL https://deb.nodesource.com/setup_12.x | sudo -E bash -
sudo apt-get install -y nodejsSnap을 설치하고 Snap으로 Neovim 설치
Neovim를 설치하기 위해 snap을 설치합니다. apt로 설치하면 0.6 보다 낮은 구버전이 설치되는데 그 버전으로는 Copilot을 쓸 수 없습니다.
sudo apt install snap
snap install nvim --classicCopilot Neovim 확장 설치
이제 Copilot 확장을 설치합니다. Github 레파지토리에서 그대로 클로닝을 해서 ~/.config 아래에 넣어주는 것이 전부입니다.
git clone https://github.com/github/copilot.vim.git ~/.config/nvim/pack/github/start/copilot.vimCopilot 활성화
이제 Neovim을 실행해서 Copilot을 활성화해야 합니다.

Neovim에서 “:Copilot setup‘ 을 입력합니다.
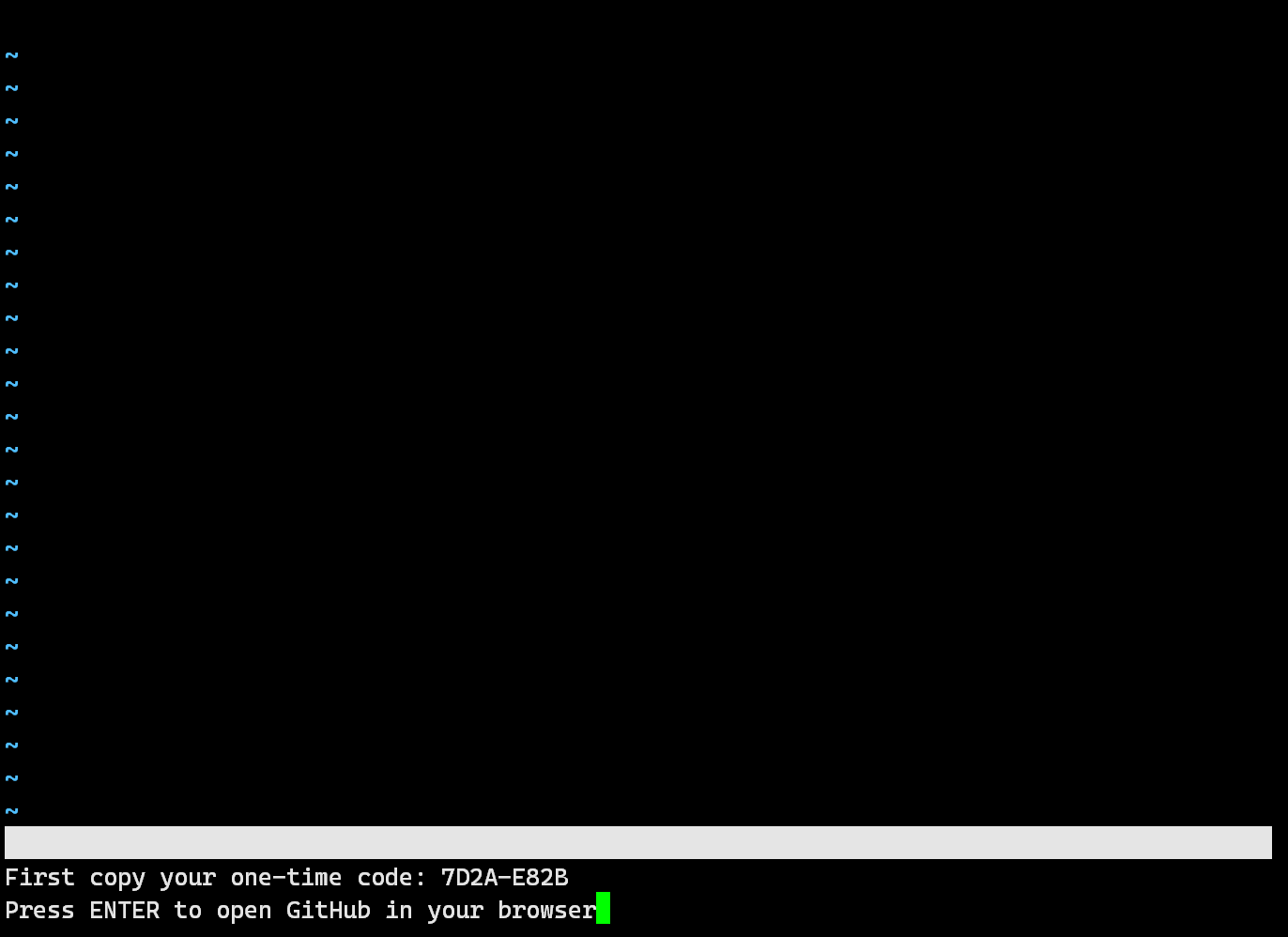
원타임 인증 코드를 보여줍니다.
하이픈을 포함해서 9개의 글자를마우스로 드래그해서 복사하세요.
웹브라우저를 열고 https://github.com/login/device 주소를 입력해서 인증 페이지로 이동합니다.

인증페이지에서 위에서 복사한 코드를 그대로 붙여넣으세요.
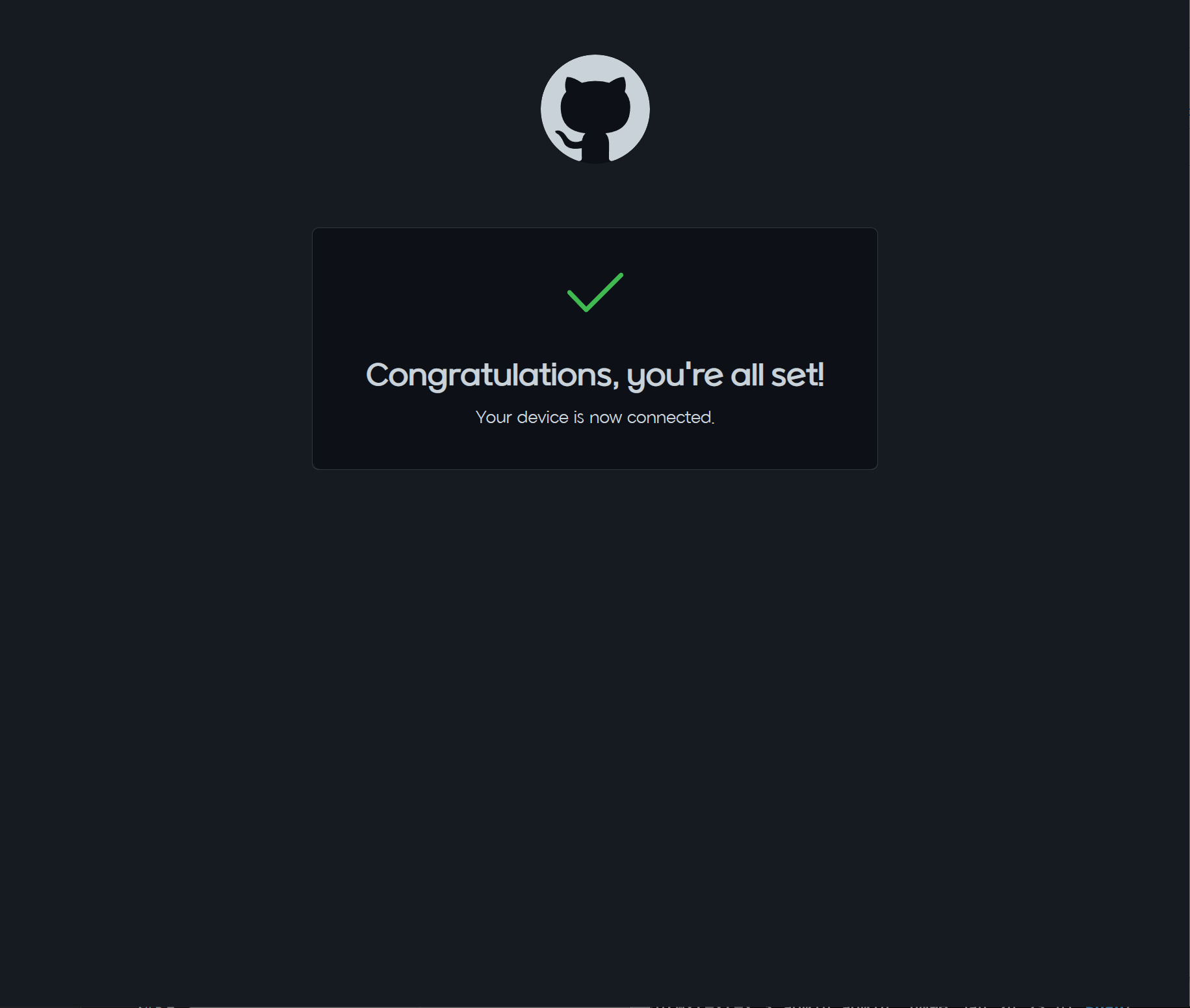
문제가 없다면 인증이 완료됩니다.

Neovim으로 돌아오면 인증이 완료된 것을 볼 수 있습니다.

Copilot이 작동하는것을 볼 수 있습니다.
이제 터미널에서도 Copilot를 쓰면서 편하게 작업할 수 있겠습니다.