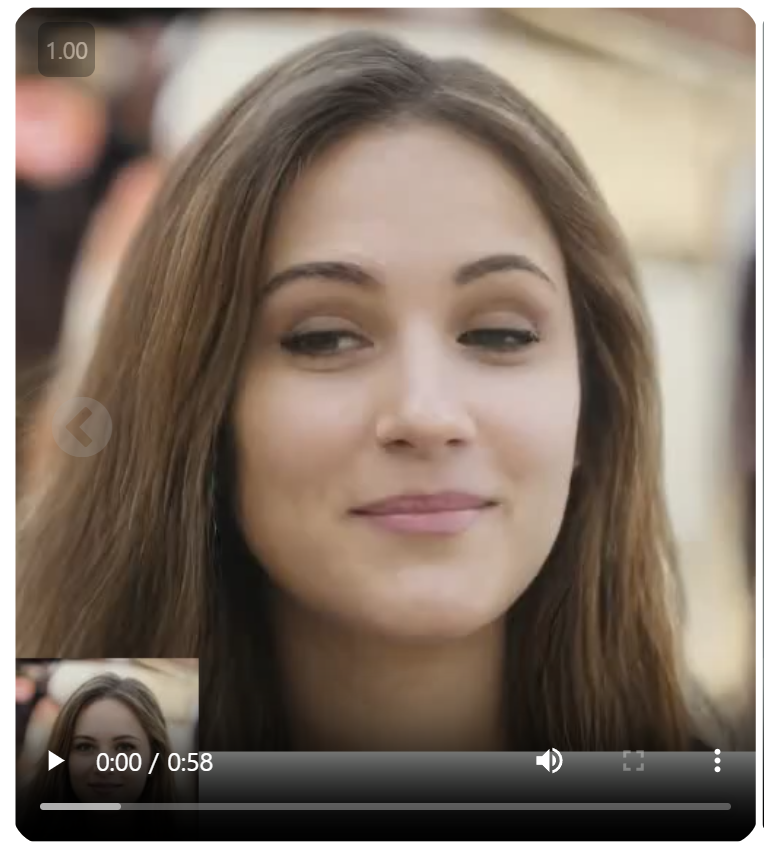
VASA-1: Lifelike Audio-Driven Talking Faces
Generated in Real Time
놀라운 모델이 또 발표되었습니다.
마이크로소프트가 사진 한장만 있으면 사진속 인물이 말을 하거나 노래를 부르는 영상으로 만들어주는 AI모델을 발표했습니다.
아래 링크에 들어가서 데모를 보시면 됩니다.
놀라운 모델이 또 발표되었습니다.
마이크로소프트가 사진 한장만 있으면 사진속 인물이 말을 하거나 노래를 부르는 영상으로 만들어주는 AI모델을 발표했습니다.
아래 링크에 들어가서 데모를 보시면 됩니다.