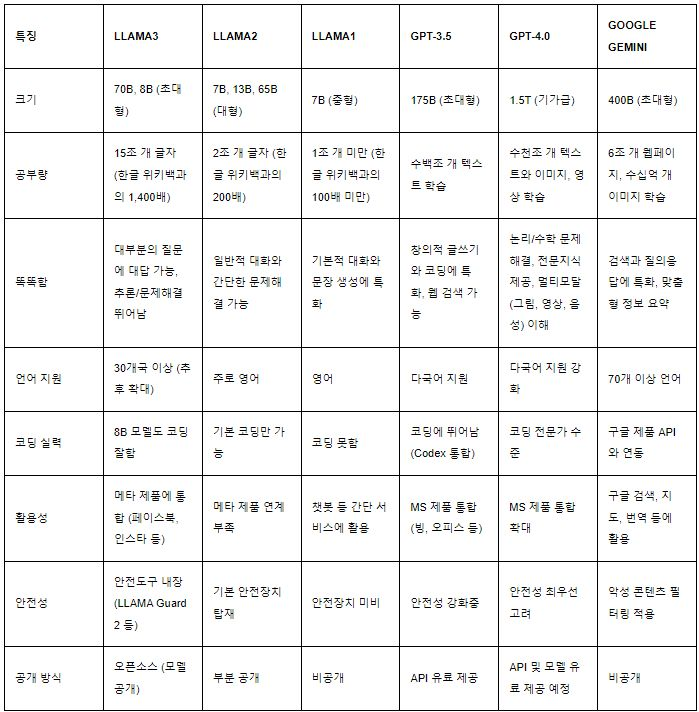
제목이 좀 기네요.
데이터브릭스 이벤트행사에 다녀왔습니다. 이 이벤트는 컨퍼런스 형식입니다.
모든 세션을 다 듣지 못했지만 들은 세션의 내용을 가지고 종합하면
좋았던 점
- 궁금한 것에 대해서 뭘 하고 있는지 어떻게 대응하고 있는지 잘 설명해줬다.
- 내용이 알찼고 섬세했다.
- 사용자의 LLM의 생성과 튜닝에 대해 준비가 어떻게 되어 있는지 잘 알려주고 있다.
- LLM을 응용한 여러가지 편의 기능과 최적화 기능 들은 인상적이었다.
아쉬운 점
- 설명할 내용이 많았는지 스피커들의 스피치속도가 빨라서 정식 없었다.
- 성공사례 발표가 많지 않았고 와닿지 않았다. 이건 다른 컨퍼런스도 마찬가지이지만 이게 아쉽네요.
- 협찬업체가 적어서 경품 부쓰가 적었다.
이렇습니다.
느낌은
무료 컨퍼런스임에도 매우 알차고 괜찮어서 만족스러웠습니다.
데이터브릭스 직원분들 능력이 좋은 것 같습니다.
사람이 많아서 많이 정신 없고 피곤했습니다. 인기 실감